
La atención es universalmente reconocida en la psicología cognitiva como un proceso cognitivo esencial que permite la selección y la concentración en estímulos que son relevantes para una tarea u objetivo. También actúa como el mecanismo de filtro y selección que regula el flujo de información desde los sentidos hacia el cerebro. Esta función es indispensable para estimular el aprendizaje de los estudiantes, permitiendo la priorización necesaria para evitar la sobrecarga sensorial (visual, auditivo, táctil) y asegurar que los recursos limitados del sistema se dirijan hacia la información más crítica.
La efectividad de la atención se clasifica jerárquicamente, según el modelo de Sohlberg y Mateer, incluyendo tipos funcionales que varían en complejidad y control :
- Arousal y Focalizada: Nivel basal de activación y la capacidad de responder a estímulos específicos.
- Sostenida (Concentración): La capacidad de mantener el foco en una tarea durante periodos prolongados, crucial para la perseverancia académica.
- Selectiva: La habilidad para concentrarse en un estímulo relevante, ignorando las distracciones circundantes.
- Alternante: La capacidad de cambiar flexiblemente el foco entre dos o más tareas con demandas cognitivas diferentes, formando la base de la flexibilidad cognitiva.
- Dividida: La habilidad para atender simultáneamente a dos o más estímulos o tareas.
Rol crítico en la memoria y la ingeniería del aprendizaje
La Atención Sostenida y la Atención Selectiva son fundamentales, ya que permiten a los individuos mantener la atención a pesar de posibles distracciones. Sin un filtro atencional selectivo y sostenido, la información de entrada no se codifica adecuadamente. En esencia, la atención funciona como una compuerta de calidad para la memoria de trabajo: si no hay foco, la codificación en la memoria a largo plazo (adquisición de conocimiento) se ve comprometida.
Los tipos de atención más complejos, como la Atención Dividida y la Atención Alternante, aunque permiten la multitarea (como estudiar mientras se escucha música), pueden llevar a un cambio constante de foco que, cuando se estimula en exceso, resulta en una reducción de la duración de la atención. La ingeniería de los modelos de IA busca replicar y optimizar la función de selección de la atención, pero buscando el paralelismo sin el costo asociado a la multitarea excesiva que experimenta el sistema cognitivo humano.
1. Génesis de los mecanismos de atención en inteligencia artificial
1.1. Limitaciones arquitectónicas de la IA secuencial previa
La necesidad de los mecanismos de atención en el aprendizaje profundo surgió de las deficiencias inherentes a las arquitecturas secuenciales dominantes a principios de la década de 2010, en particular las Redes Neuronales Recurrentes (RNN).
- Problemas de dependencia a largo plazo: Las RNNs simples eran difíciles de entrenar debido a la inestabilidad de los gradientes (desvanecimiento), lo que impedía que la red aprendiera dependencias entre elementos distantes en una secuencia. Las redes de Memoria a Largo y Corto Plazo (LSTM) mitigaron este problema mediante puertas de control, pero el procesamiento subyacente seguía siendo secuencial.
- Cuello de botella del contexto fijo: Las arquitecturas sequence-to-sequence (Seq2Seq) convencionales, utilizadas para la traducción automática, forzaban al codificador a comprimir toda la información de la frase de entrada en un único vector de contexto de longitud fija, sin importar la extensión de la secuencia fuente. Al aumentar la longitud de la secuencia, este vector único resultaba insuficiente para retener todos los matices semánticos y sintácticos, creando un severo cuello de botella de rendimiento.
- Sesgo recurrente: La estructura de las RNNs favorecía intrínsecamente la información más reciente (palabras al final de una frase), mientras que la información al principio de la secuencia tendía a atenuarse, dificultando la retención de contexto inicial.
1.2. La introducción del concepto de «Atención» en IA
El mecanismo de atención fue desarrollado para abordar estas debilidades en el uso de la información de las capas ocultas de las redes recurrentes.
El Creador y la obra fundacional:
El concepto de atención en la inteligencia artificial fue introducido por Bahdanau, Cho y Bengio et al. en el año 2014, en su artículo seminal «Neural Machine Translation by Jointly Learning to Align and Translate«.
El aporte principal de Bahdanau fue proponer que, en lugar de que el decodificador dependiera de un único vector de contexto estático, se le permitiera decidir dinámicamente qué partes de la frase fuente debían ser atendidas (alineadas) al generar cada palabra de la traducción. Al permitir que el decodificador tuviera este mecanismo de atención, se liberó al codificador de la carga de tener que comprimir toda la información en un vector de longitud fija. Este enfoque sentó las bases para todos los modelos modernos de procesamiento de secuencias.
2. Mecanismos de atención
Los mecanismos de atención son componentes clave en los modelos de IA que permiten a la red centrarse en partes específicas de la entrada o contexto, «ponderando su importancia» durante la ejecución de una tarea. Esta ponderación de importancia mejora significativamente la capacidad de comprensión y toma de decisiones.
2.1. Clasificación por función de puntuación (Aditiva vs. Multiplicativa)
La manera en que se calcula la relevancia (o puntuación de alineación) entre la información de entrada y el estado de la tarea define dos tipos principales de atención, que fueron precursores de la Autoatención moderna:
2.1.1. Atención aditiva (Bahdanau)
La atención aditiva, o por concatenación, propuesta por Bahdanau et al., emplea una red neuronal feed-forward para calcular las puntuaciones de atención.
- Mecanismo: La función de alineación combina el estado oculto del decodificador anterior y las anotaciones generadas por el codificador utilizando una «operación de suma (aditiva)», seguida de la aplicación de la función tangente hiperbólica (tanh).
- Parámetros y Complejidad: Este enfoque es más complejo y computacionalmente costoso porque introduce un mayor número de parámetros entrenables (varias matrices de peso). Esto le otorga mayor flexibilidad para modelar relaciones no lineales intrincadas entre los estados del codificador y decodificador.
2.1.2. Atención multiplicativa (Luong / producto punto)
La atención multiplicativa, asociada a Luong et al., utiliza enfoques matemáticos más simples y directos, como el producto escalar, para calcular las puntuaciones de atención.
- Mecanismo: El cálculo se realiza mediante la multiplicación (producto escalar) entre el estado actual del decodificador y los estados ocultos del codificador.
- Requisito y Eficiencia: Una consecuencia de utilizar el producto escalar es que los cálculos requieren que los vectores de consulta y clave tengan la misma dimensión. Este mecanismo es más simple, directo y computacionalmente eficiente ya que utiliza menos parámetros entrenables.
La simplicidad y eficiencia de la atención de producto punto, en una versión escalada, fue la elegida para la arquitectura Transformer, superando a la atención aditiva en el contexto de la escalabilidad masiva.
2.2. Clasificación por alcance (Soft Attention vs. Hard Attention)
2.2.1. Soft Attention.
La atención suave es el mecanismo más común y es el utilizado en la arquitectura Transformer.
- Mecanismo: Es un proceso determinístico y exhaustivo que considera la totalidad del input. Asigna un peso continuo (entre 0 y 1) a cada parte del input, y el vector de contexto resultante es una suma ponderada de todas las partes.
- Optimización: Su principal ventaja es que es completamente diferenciable. Esto permite utilizar la retropropagación estándar para ajustar los pesos, lo cual es esencial para el entrenamiento de modelos de gran escala.
2.2.2. Hard Attention.
La atención dura se inspira más directamente en la atención focalizada humana, que selecciona un punto específico.
- Mecanismo: Realiza una decisión binaria o estocástica, seleccionando solo partes específicas del input para enfocarse, mientras que ignora el resto (asigna peso 1 o 0). Por ejemplo, en el subtitulado de imágenes, selecciona los píxeles más relevantes.
- Desafío: Es un proceso no diferenciable debido a la operación de muestreo estocástico (selección binaria).
- Optimización: Para calcular los gradientes y optimizar el modelo, se requiere el uso de técnicas de «Aprendizaje por Refuerzo (RL) » o métodos de muestreo como Monte Carlo, lo que introduce una complejidad significativa al entrenamiento.
La Soft Attention es la opción dominante en la IA contemporánea debido a su sencillez de entrenamiento, que compensa cualquier potencial pérdida de precisión de foco con una robusta capacidad de paralelización y escalabilidad.
3. Autoatención y multi-cabeza (multi-head): La Arquitectura del Transformer
3.1. El Mecanismo QKV (Query, Key, Value) en la Autoatención
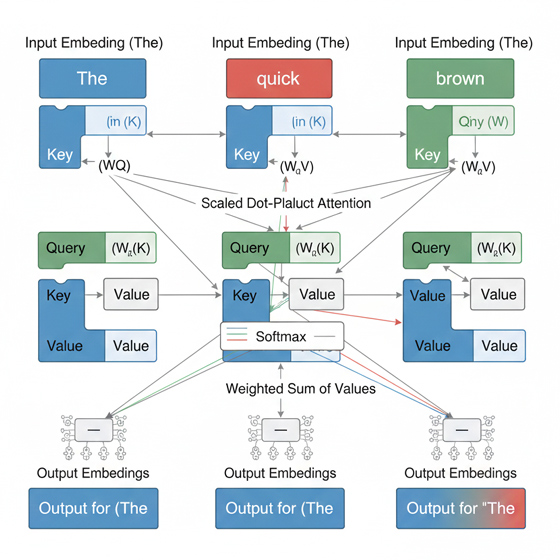
La Autoatención (Self-Attention) es un caso especial de atención donde los Query, Key y Value provienen de la misma secuencia de entrada. Este mecanismo es el pilar de la arquitectura Transformer y permite a los diferentes tokens de una secuencia ponderar su importancia relativa con respecto a todos los demás tokens.
La autoatención utiliza el modelo Query-Key-Value (QKV), donde la representación vectorial de cada palabra (o token) se transforma linealmente en tres proyecciones distintas :
- Query (Q): Actúa como la pregunta que busca información contextual.
- Key (K): Actúa como el índice o etiqueta para el contenido disponible en la secuencia.
- Value (V): Representa el contenido real de la información a ser extraída.
Funcionamiento paso a paso:
- Cálculo de Relevancia: Para determinar el contexto de un token específico (representado por su Q), se calcula el producto escalar (dot product) entre su Q y todas las K de la secuencia. Esto genera una matriz de puntuaciones de atención (relevancia).
- Ponderación: Estas puntuaciones se normalizan y escalan, convirtiéndose en pesos que indican cuán importante es cada token para el token consultante.
- Agregación Contextual: Finalmente, la salida contextualizada se calcula como la suma ponderada de los vectores V, donde los pesos son las puntuaciones de atención calculadas.
Este proceso permite que un token acceda directamente y con igual oportunidad a cualquier otra parte de la secuencia. Esto elimina la limitación de favorecer la información reciente (propia de las RNN) y permite la captura eficiente de dependencias a largo plazo, ya que la comunicación entre dos tokens distantes solo requiere una operación matricial.
3.2. La potencia del paralelismo: Atención multi-cabeza (Multi-Head Attention)
Si bien la Autoatención es poderosa, depender de un único cálculo de atención limita la capacidad del modelo para enfocarse simultáneamente en diferentes tipos de relaciones o aspectos del input. La Atención Multi-Cabeza (Multi-Head Attention) resuelve esto ejecutando múltiples funciones de atención en paralelo.
Mecanismo de la Multi-Cabeza:
El proceso se implementa mediante la división lógica de los vectores Q, K y V en múltiples subespacios de menor dimensión, denominados cabezas de atención (h).
\[\text{head}_i = \text{Attention}(\mathbf{Q}\mathbf{W}_i^Q, \mathbf{K}\mathbf{W}_i^K, \mathbf{V}\mathbf{W}_i^V)\] \[\text{MultiHead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h)\mathbf{W}_O\]Donde Wi son las matrices de proyección de cada cabeza.
Ventaja Semántica: Esta división lógica significa que secciones separadas del vector Embedding original pueden aprender diferentes aspectos de los significados de las palabras en relación con el resto de la secuencia. Por ejemplo, una cabeza podría especializarse en relaciones sintácticas (ej. sujeto-verbo), mientras que otra se enfoca en relaciones semánticas (ej. correferencia). Al concatenar los resultados de estas h cabezas, el modelo logra una comprensión contextual más rica y matizada del dato de entrada. Este enfoque paralelo actúa como un ensamble de expertos, incrementando la robustez y la capacidad de codificación del Transformer.
3.3. Tipos de autoatención en el contexto del Transformer
La arquitectura Transformer (codificador-decodificador) utiliza tres sub-capas de atención diferentes:
- Autoatención del Codificador (Encoder Self-Attention): Permite a cada token de la entrada (fuente) interactuar con todos los demás tokens de la entrada para formar una representación de contexto global.
- Autoatención enmascarada del Decodificador (Masked Decoder Self-Attention): Permite a los tokens de la salida generada hasta el momento interactuar entre sí. El enmascaramiento asegura que la atención de un token no se extienda a tokens futuros, preservando la propiedad auto-regresiva (generación secuencial).
- Atención cruzada del Decodificador (Encoder-Decoder Attention): Esta capa enlaza las salidas del codificador (donde K y V se toman de las salidas del codificador) con el estado parcial del decodificador (donde Q se toma de la capa previa del decodificador). Su función es alinear la palabra que se está generando en la salida con las partes más relevantes de la secuencia de entrada.
4. Tipos de atención aplicados a dominios específicos
El concepto de atención se ha extendido más allá del Procesamiento de Lenguaje Natural (NLP) para transformar el campo de la Visión por Computadora (CV) y otras áreas.
4.1. Aplicaciones en NLP y modelos de lenguaje masivos
En NLP, la atención es fundamental para la generación de texto coherente. Permite que el modelo, al generar una palabra, identifique el contexto más relevante en la frase. El éxito de la atención ha llevado a mejoras significativas en:
- Traducción y Resumen Automático: Permite a los modelos enfocarse en las partes más informativas del texto para condensar o traducir con precisión contextual.
- Comprensión de Lenguaje Natural (NLU): La atención permite a los modelos de lenguaje encontrar significados similares en frases diferentes y realizar la desambiguación del sentido de las palabras al considerar todo el contexto.
4.2. Aplicaciones en visión por computadora y vision Transformers (ViT)
Los mecanismos de atención han revolucionado la Visión por Computadora (CV) al mejorar la capacidad de las redes neuronales para enfocarse dinámicamente en las partes más relevantes de una imagen. Esto imita la atención visual humana.
El Vision Transformer (ViT) es una arquitectura que aplica la Autoatención del Transformer al dominio visual. En lugar de depender de convoluciones para capturar características locales, los ViT tratan una imagen como una secuencia de parches. Esto permite al mecanismo Multi-Head Self-Attention (MSA) modelar relaciones globales (dependencias a largo plazo) entre diferentes partes de la imagen, logrando un rendimiento superior en tareas como clasificación de imágenes, detección de objetos y comprensión de escenas.
Los mecanismos de atención en CV se clasifican a menudo según la dimensión de la característica a la que dan prioridad:
4.2.1. Atención Espacial (Spatial Attention)
La atención espacial se centra en las ubicaciones o regiones importantes dentro de una imagen. Asigna pesos a diferentes coordenadas espaciales, dirigiendo al modelo a concentrarse en las áreas que son más relevantes para la tarea (ej., dónde está el objeto). Un ejemplo práctico es su uso en sistemas de detección de objetos como YOLO.
4.2.2. Atención de Canal (Channel Attention)
La atención de canal enfatiza la importancia de diferentes canales de características (feature maps). Al asignar pesos a cada canal (que representan distintos tipos de información, como color, bordes o textura), el modelo puede realzar o suprimir características específicas. Este enfoque permite al modelo decidir qué tipo de información (la característica) es más útil para el procesamiento.
La combinación de atención espacial y de canal permite que la red refine las representaciones de características de forma robusta, asegurando que el modelo preste atención tanto a la ubicación crítica como a las «características clave» del dato visual.
5. Conclusiones
La atención, inicialmente definida como un proceso cognitivo fundamental para el aprendizaje humano, ha proporcionado el paradigma esencial para una revolución en el aprendizaje profundo (Deep Learning).
El punto de inflexión fue la introducción de un mecanismo de alineación dinámico por Bahdanau, Cho, y Bengio et al. en 2014. Esta idea evolucionó rápidamente para convertirse en la Autoatención y la Atención Multi-Cabeza, que forman la base del Transformer, eliminando la necesidad de recurrencia y permitiendo el procesamiento paralelo de secuencias.
La atención artificial opera mediante la ponderación de la relevancia (mecanismo QKV) para generar representaciones contextuales ricas, lo que ha impulsado avances sin precedentes en la traducción, la generación de lenguaje (LLMs) y la visión por computadora (ViT).
Sin embargo, el éxito de la Autoatención está limitado por su costo computacional cuadrático con respecto a la longitud de la secuencia. Este desafío impone una barrera física a la extensión del contexto en los modelos de IA masivos. La investigación futura se orienta necesariamente a mantener el poder relacional y global de la atención mientras se reduce su complejidad computacional para permitir la construcción de modelos con capacidad de contexto significativamente mayor.
————————————————————————————————
Fuentes: