La búsqueda de la inteligencia artificial (IA) ha sido una ambición recurrente en la historia de la ciencia y la tecnología. Desde los primeros intentos de crear autómatas capaces de realizar tareas lógicas, el desafío fundamental ha sido replicar o emular las capacidades cognitivas del cerebro humano. Sin embargo, este esfuerzo se topó con un dilema intrínseco: para replicar la inteligencia, es necesario comprender por completo su mecanismo, una tarea que sigue siendo uno de los grandes misterios de la neurociencia. Ante esta barrera, la comunidad científica adoptó un enfoque diferente. En lugar de buscar una réplica exacta del cerebro, se propuso un modelo que emulara sus principios de procesamiento de información, incluso si de manera simplificada. De esta necesidad surgió la neurona artificial. Esta abstracción matemática no pretendía ser una copia fidedigna, sino un componente elemental de software capaz de imitar las funciones más básicas de su contraparte biológica: recibir información, procesarla y producir una respuesta.
1. Definición y la analogía biológica de la neurona artificial
1.1. El concepto fundamental
En su esencia más pura, una neurona artificial es un módulo de software o un nodo, que sirve como la unidad elemental de procesamiento de información dentro de las redes neuronales artificiales (RNA). Las RNA, a su vez, son programas o algoritmos diseñados para utilizar sistemas computacionales con el fin de resolver cálculos matemáticos complejos. La potencia de este enfoque radica en su capacidad de interconexión. Al igual que en el cerebro, donde miles de millones de neuronas se conectan para formar una red masiva, las neuronas artificiales se agrupan en capas que, de manera colectiva, son capaces de aprender de los datos y realizar tareas complejas como el reconocimiento de patrones o la toma de decisiones.
1.2. La Inspiración biológica: Una analogía en cuatro partes
La estructura de la neurona artificial está directamente inspirada en la neurona biológica, aunque de forma abstracta y simplificada. Esta analogía es crucial para comprender su funcionamiento:
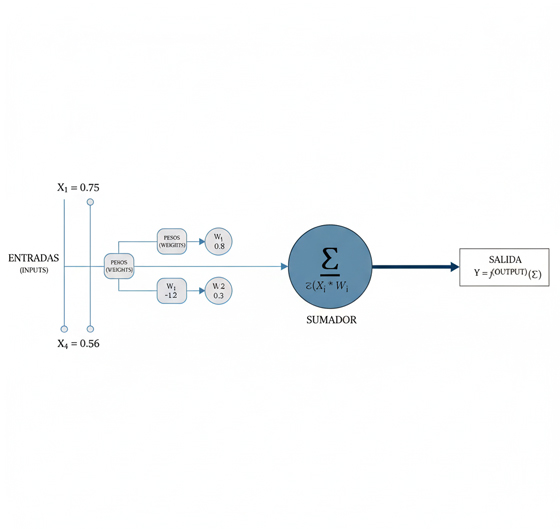
- Entradas (Inputs) y Dendritas: En una neurona biológica, las dendritas son las ramificaciones que reciben las señales eléctricas de otras neuronas. De manera análoga, una neurona artificial recibe una serie de valores de entrada (
x), que son las señales de datos que llegan al nodo. - Pesos (Weights) y Sinapsis: Las sinapsis son las conexiones entre neuronas biológicas, y su fuerza o eficacia determina la magnitud con la que una señal es transmitida. En el modelo artificial, esta fuerza se representa mediante los pesos (
w), que son valores numéricos que determinan la importancia o la fuerza de la conexión entre dos nodos. Un peso alto indica una mayor influencia de la entrada en la salida del nodo siguiente. - Sumador y Soma: El soma, o cuerpo celular de la neurona biológica, integra todas las señales recibidas a través de las dendritas. Estas señales pueden ser excitatorias o inhibitorias, y su suma determina si la neurona se activa. La neurona artificial imita este proceso con una simple pero poderosa operación: realiza una suma ponderada de sus entradas, multiplicando cada valor de entrada por su peso correspondiente y sumando los resultados (
Σ w*x). - Salida (Output) y Axón: Cuando la suma de las señales en una neurona biológica alcanza un umbral, se produce un potencial de acción que se transmite a lo largo del axón para ser enviado a otras neuronas. De igual modo, la neurona artificial toma el resultado de la suma ponderada y lo pasa a través de una función de activación, que determina la salida final (
y). Esta salida se propaga a la siguiente capa de la red, completando el ciclo de procesamiento.
La analogía biológica es más que una simple metáfora; es el fundamento del poder de modelado de las redes neuronales. Los neurocientíficos se dieron cuenta de que las neuronas biológicas no responden de manera lineal a los estímulos; su respuesta es no necesariamente proporcional a la entrada eléctrica. Por ejemplo, una entrada muy débil puede no generar ninguna respuesta, pero una entrada que supera un umbral puede provocar una activación completa. Este comportamiento no lineal es crucial para que el cerebro pueda realizar funciones complejas. Al diseñar la neurona artificial, los creadores no buscaron una réplica perfecta de la biología, sino que capturaron este principio clave: la capacidad de tomar una decisión compleja basada en una suma ponderada y un umbral, en lugar de una simple relación lineal. Esta intuición, la de que la no linealidad es esencial para modelar la complejidad del mundo real, es el corazón de la diferencia entre los modelos de machine learning tradicionales y las redes neuronales.
2. Hitos históricos y pioneros del Modelo
2.1. Los orígenes lógicos (1943): El modelo de McCulloch-Pitts
El primer modelo matemático de la neurona artificial fue propuesto en 1943 por el neurofisiólogo Warren McCulloch y el lógico Walter Pitts en su influyente artículo “A Logical Calculus of the ideas Imminent in Nervous Activity”. Inspirándose en los trabajos de Alan Turing, el modelo de McCulloch-Pitts describía un método para representar las funciones cerebrales en términos abstractos y demostró que elementos simples interconectados en una red neuronal podían tener un “inmenso poder computacional”. Este modelo operaba con entradas y salidas binarias y utilizaba una función de activación de umbral, lo que permitía la implementación de funciones lógicas booleanas como AND y OR. Aunque teóricamente sólido, el modelo inicial recibió poca atención y su importancia no fue plenamente reconocida hasta que otros investigadores comenzaron a aplicarlo.
2.2. La era del perceptrón (1957): Frank Rosenblatt
El modelo de McCulloch-Pitts sentó las bases, pero fue Frank Rosenblatt quien creó la primera implementación práctica de una neurona artificial que podía aprender: el Perceptrón. Desarrollado en 1957, el Perceptrón era una estructura con una capa de entrada y una de salida, diseñada para la clasificación binaria. Demostró un avance significativo hacia el aprendizaje automático, pero se encontró con una limitación fundamental. En 1969, Marvin Minsky y Seymour Papert publicaron su libro Perceptrons, en el que demostraron que este tipo de red no podía resolver problemas no lineales como la función XOR (o-exclusivo). Este descubrimiento provocó una drástica reducción en el interés y la financiación de la investigación en redes neuronales, un periodo que se conoció como el «invierno de la IA». La historia de este estancamiento revela una dinámica compleja: la limitación teórica de un modelo (el Perceptrón) creó una crisis de confianza que llevó a una falta de financiación. Esta falta de inversión, a su vez, impidió la investigación que podría haber resuelto precisamente esa limitación, creando un ciclo de retroalimentación negativa que detuvo el progreso en el campo por muchos años.
2.3. El renacimiento (1980s): La retropropagación
El resurgimiento del campo de las redes neuronales a partir de la década de 1980 fue impulsado en gran medida por la introducción del algoritmo de retropropagación (backpropagation), una técnica clave en cuyo desarrollo Geoffrey Hinton fue una figura central. La retropropagación finalmente permitió superar el problema de la no linealidad que había condenado al Perceptrón simple. El algoritmo funciona calculando el error entre la salida de la red y la salida deseada. Luego, propaga este error hacia atrás, desde la capa de salida hasta las capas anteriores, ajustando los pesos de cada neurona de manera iterativa para minimizar el error en cada iteración. Este avance algorítmico hizo posible entrenar redes neuronales con múltiples capas, resolviendo por fin el problema de la no linealidad que había marcado el inicio del «invierno de la IA».
2.4. El auge del Deep Learning (2000-2010)
Con el algoritmo de retropropagación y la nueva comprensión de cómo entrenar redes multicapa, el escenario estaba listo para la siguiente gran revolución. Sin embargo, el verdadero auge del deep learning (aprendizaje profundo) no se produjo hasta la década de 2000, impulsado por una confluencia de factores. En primer lugar, la capacidad de cómputo había crecido exponencialmente, con la llegada de las unidades de procesamiento gráfico (GPU) de alto rendimiento que eran perfectas para los cálculos matriciales masivos que requieren las redes neuronales.
En segundo lugar, la disponibilidad de enormes volúmenes de datos, conocidos como Big Data, proporcionó el combustible necesario para entrenar modelos de una complejidad sin precedentes. El deep learning, que es un subcampo del machine learning que utiliza redes neuronales con múltiples capas ocultas, aprovechó estos avances para lograr hitos notables, como el desarrollo de las redes neuronales convolucionales (CNN) para el reconocimiento de imágenes y las redes recurrentes (RNN) para el procesamiento de lenguaje natural. La historia de la neurona artificial es, por lo tanto, un ciclo de avance, limitación, estancamiento y renacimiento, un claro ejemplo de cómo la innovación en la IA depende de la convergencia de avances teóricos, la disponibilidad de datos y la capacidad del hardware.
3. Anatomía y mecanismos de funcionamiento detallados
3.1. La arquitectura de una red neuronal
Una red neuronal artificial está estructurada en capas de neuronas interconectadas que procesan la información de manera secuencial. La arquitectura más básica consta de tres tipos de capas :
- Capa de Entrada: Es la primera capa de la red y recibe los datos brutos del entorno externo, ya sea una imagen, un texto o datos numéricos. Los nodos de esta capa procesan la información y la pasan a la siguiente capa.
- Capas Ocultas: Estas capas se encuentran entre la capa de entrada y la de salida. Una red puede tener una o muchas de estas capas. El término «profundo» en deep learning se refiere precisamente a las redes que tienen un gran número de capas ocultas. En estas capas se realizan cálculos complejos y se extraen características de los datos que la capa anterior le proporcionó.
- Capa de Salida: Esta capa produce el resultado final del procesamiento. Puede tener uno o múltiples nodos, dependiendo de la tarea. Por ejemplo, en un problema de clasificación binaria (sí/no), la capa de salida tendrá un solo nodo con un resultado de 1 o 0.
3.2. Los componentes internos de una neurona artificial
Cada neurona dentro de esta arquitectura opera en base a tres componentes clave:
3.2.1. Entradas y pesos (Inputs & Weights)
Las entradas son los valores de los datos que alimentan a la neurona, mientras que los pesos (w) son los valores numéricos que se multiplican por cada entrada. Los pesos son la variable de «aprendizaje» del modelo. El entrenamiento de una red neuronal es un proceso iterativo en el que estos pesos se ajustan y refinan para que la red minimice el error de sus predicciones. Este proceso es el mecanismo por el cual los modelos de aprendizaje automático aprenden a reconocer patrones y a hacer predicciones precisas a partir de nuevos datos.
3.2.2. Sesgo (Bias): El desplazamiento fundamental
El sesgo (b), también conocido como bias, es un parámetro adicional que se suma al producto de la suma ponderada (Σ w*x) de las entradas. Su función es crucial: controla la facilidad con la que una neurona se activa, independientemente de la suma ponderada de las entradas. Un sesgo alto hace que la neurona requiera una entrada más alta para activarse, mientras que un sesgo bajo hace que la activación sea más fácil. La importancia del sesgo se puede entender con la analogía de la ecuación de la recta «y = mx + b«, donde el sesgo es la intersección con el eje «y«. Sin este término, la salida de la neurona siempre tendría que pasar por el origen (cero). En el mundo real, las relaciones entre datos rara vez comienzan en cero. Por ejemplo, la altura de un ser humano no es cero, incluso si su ingesta calórica fuera cero. El sesgo proporciona al modelo la flexibilidad necesaria para representar una gama mucho más amplia de patrones de datos, permitiendo que la recta de decisión se desplace verticalmente para ajustarse mejor a los datos.
3.2.3. La función de activación: El corazón no lineal
La función de activación es el componente que introduce no linealidad en el modelo. Sin ella, una red neuronal con múltiples capas ocultas sería matemáticamente equivalente a una red de una sola capa, lo que limitaría su poder de modelado a resolver solo problemas lineales. Las funciones de activación permiten a la red aprender relaciones complejas que no pueden ser representadas por una simple regresión lineal.
A continuación se presenta una tabla que compara las funciones de activación más comunes en el campo del deep learning:
| Funcion | Aspectos Principales |
| Lineal f(x)=x Rango salida: (−∞,∞) | No altera la salida; simple. Rara vez usada en capas ocultas; limita el modelo a relaciones lineales. |
| Sigmoide \[\sigma(x) = \frac{1}{1 + e^{-x}}\] Rango salida: (0,1) | Salida interpretable como probabilidad; ideal para clasificación binaria. Sufre de «desvanecimiento de gradiente» en redes profundas. |
| ReLU f(x)=max(0,x) Rango salida: [0,∞) | Computacionalmente eficiente; mitiga el problema de desvanecimiento de gradiente. Es una función no lineal; puede causar neuronas «muertas» para entradas negativas. |
| Softmax \[P(y_j = 1 | \mathbf{z}) = \frac{e^{z_j}}{\sum_{k=1}^{K} e^{z_k}}\] Rango salida: (0,1) | Convierte salidas en una distribución de probabilidad; ideal para clasificación multiclase. Se utiliza típicamente en la capa de salida; puede ser sensible a valores atípicos. |
4. La revolución: Por qué la neurona artificial desplazó al ML tradicional
4.1. La brecha de la ingeniería de características (Feature Engineering)
La principal razón por la que las redes neuronales desplazaron a los modelos de machine learning tradicionales, como la regresión logística o los árboles de decisión, radica en la gestión de las características de los datos. Los modelos tradicionales requerían que un experto humano realizara manualmente la «ingeniería de características», un proceso laborioso y propenso a errores en el que se extraían las variables más relevantes de los datos para que el modelo pudiera interpretarlos. En una tarea de reconocimiento de imágenes, por ejemplo, esto significaba que un programador tenía que escribir reglas para identificar características como bordes, esquinas o el color dominante. Este enfoque era un cuello de botella y no escalaba bien.
En contraste, el deep learning eliminó por completo esta necesidad. Las redes neuronales profundas tienen la capacidad de aprender y extraer automáticamente las características más relevantes directamente de los datos brutos, ya sean imágenes, texto o audio no estructurado. Cada capa de la red se especializa en extraer un nivel de abstracción cada vez mayor, pasando de identificar bordes en las primeras capas a reconocer objetos completos en las capas más profundas. Este cambio de paradigma, de un enfoque basado en reglas humanas a uno donde la máquina aprende a derivar sus propias reglas, es el verdadero legado de la neurona artificial.
4.2. Escala, complejidad y rendimiento
El poder de la neurona artificial se manifiesta especialmente a gran escala. A diferencia de los modelos tradicionales, que alcanzan un rendimiento que se estabiliza más rápidamente con grandes volúmenes de datos, el rendimiento de las redes neuronales continúa mejorando a medida que se les proporciona más información. Esto las hizo el modelo perfecto para la era del Big Data. Este poder, sin embargo, viene con un costo computacional significativo. Los modelos tradicionales son generalmente más simples y requieren menos potencia de cómputo, mientras que el entrenamiento de redes neuronales profundas es más complejo y necesita hardware de alto rendimiento como GPUs.
Esta inversión en recursos se justifica por la precisión superior que ofrecen. En tareas de alta complejidad como el reconocimiento facial, el procesamiento de lenguaje natural y el diagnóstico médico a partir de imágenes, las redes neuronales han alcanzado, y en muchos casos superado, el rendimiento de los expertos humanos.
4.3. Versatilidad y nuevas aplicaciones
El impacto de las redes neuronales se ha sentido en una amplia gama de aplicaciones que eran inalcanzables para los modelos tradicionales. Desde el diagnóstico médico automatizado y el análisis financiero hasta los asistentes virtuales como Amazon Alexa, la neurona artificial ha servido como la base para sistemas capaces de resolver problemas complejos con una precisión sin precedentes. Por ejemplo, las CNN se usan para inspeccionar y detectar defectos en las carrocerías de los vehículos , mientras que los modelos de procesamiento de lenguaje natural (NLP) basados en redes neuronales pueden entender y clasificar conversaciones, lo que ha revolucionado el desarrollo de chatbots.
5. Conclusión
5.1. Recapitulación de los puntos clave
El viaje de la neurona artificial es una historia de perseverancia científica. Desde una idea teórica de McCulloch y Pitts, pasando por el primer intento práctico de Rosenblatt y el subsiguiente «invierno de la IA», hasta el renacimiento impulsado por la retropropagación y el auge del deep learning con el Big Data y las GPUs, la neurona artificial ha demostrado ser el bloque de construcción fundamental que permite a los sistemas computacionales modelar relaciones complejas y no lineales. Es el componente central que ha redefinido el machine learning, al permitir que las máquinas no solo tomen decisiones, sino que aprendan a derivar sus propias reglas a partir de la experiencia.
5.2. Desafíos actuales y futuras direcciones
A pesar de sus éxitos, las redes neuronales enfrentan desafíos significativos. Uno de los principales es el problema de la «caja negra», donde la complejidad de las redes profundas dificulta la comprensión de por qué toman ciertas decisiones, lo que plantea preocupaciones sobre la transparencia y la ética de la IA. Además, la dependencia de enormes conjuntos de datos y la necesidad de hardware de alta potencia sigue siendo una limitación. En respuesta a esto, la investigación se está moviendo hacia el desarrollo de redes más ligeras y eficientes, aptas para ser implementadas en dispositivos periféricos (Edge AI) como teléfonos inteligentes y dispositivos de Internet de las Cosas (IoT). También hay un campo prometedor en el desarrollo de neuronas artificiales físicas, como las que utilizan memristores de baja potencia, que podrían funcionar con voltajes biológicos y comunicarse directamente con las neuronas reales.
5.3. Reflexión final
En retrospectiva, el descubrimiento de la neurona artificial no solo proporcionó una alternativa a los modelos de machine learning tradicionales; marcó un cambio de paradigma fundamental. Anteriormente, el aprendizaje automático era un proceso de «enseñanza supervisada» donde los humanos extraían las características y el modelo aprendía a relacionarlas con una salida. Con la neurona artificial, la relación se invirtió. Ahora, los sistemas pueden aprender a extraer esas características por sí mismos, lo que ha abierto la puerta a la automatización de tareas de alta complejidad que antes requerían una intervención humana extensa. En este sentido, la neurona artificial no simplemente desplazó a los modelos tradicionales; inauguró una nueva era en la que la inteligencia artificial se vuelve más autónoma, adaptable y, en última instancia, más inteligente.
————————————————
Fuentes: