
El panorama de la inteligencia artificial (IA) ha evolucionado rápidamente, pasando de ser un campo de investigación a convertirse en un motor fundamental para la toma de decisiones empresariales. En este contexto, surge MLOps, una disciplina esencial para la gestión eficiente y fiable de los modelos de aprendizaje automático (ML) a lo largo de todo su ciclo de vida.
¿Qué es MLOps?
MLOps, acrónimo de Machine Learning Operations, representa un conjunto de prácticas y principios diseñados para gestionar el ciclo de vida completo del aprendizaje automático. Este abarca desde las etapas iniciales de desarrollo y experimentación hasta el despliegue en entornos de producción y el monitoreo continuo de los modelos de IA. Fundamentalmente, MLOps se concibe como la fusión de Machine Learning (ML) y DevOps, adoptando las metodologías de automatización, colaboración y entrega continua (CI/CD) y adaptándolas a las particularidades y desafíos inherentes al desarrollo y operación de sistemas de ML.
El propósito central de MLOps es cerrar la brecha que históricamente ha existido entre los equipos de científicos de datos, responsables del desarrollo y la experimentación de modelos, y los equipos de operaciones e ingeniería, encargados de la puesta en producción y el mantenimiento de estos sistemas. Al establecer un marco de trabajo consistente y fiable, MLOps asegura que los modelos de ML no solo se desarrollen de manera efectiva, sino que también se prueben rigurosamente, se desplieguen de forma predecible y se mantengan con un rendimiento óptimo en entornos operativos reales.
¿Por qué MLOps es Crucial en el Ciclo de Vida de la IA?
La creciente dependencia de las organizaciones en los modelos de ML para impulsar decisiones empresariales críticas ha elevado la importancia de MLOps a un nivel estratégico. La fiabilidad, escalabilidad y mantenibilidad de estos modelos en producción son aspectos no negociables para el éxito de las iniciativas de IA. Las prácticas informales o manuales, que pueden ser adecuadas en las fases experimentales, resultan insuficientes y propensas a errores cuando se trata de sistemas de IA que operan a gran escala y afectan directamente los resultados del negocio. Por lo tanto, la adopción de MLOps se convierte en una necesidad imperativa para la madurez de la IA en las empresas.
La implementación de MLOps confiere una serie de beneficios clave que justifican su adopción:
- Mayor eficiencia: MLOps automatiza y optimiza el ciclo de vida del ML, lo que se traduce en una reducción significativa del tiempo y el esfuerzo requeridos para desarrollar, desplegar y mantener modelos. Esta automatización libera a los científicos de datos e ingenieros de tareas repetitivas y de bajo valor, permitiéndoles concentrarse en actividades de mayor impacto, como la innovación y la mejora de algoritmos.
- Mayor escalabilidad: La capacidad de escalar las operaciones de ML es fundamental a medida que las organizaciones manejan volúmenes de datos cada vez mayores y modelos más complejos. MLOps proporciona el marco y las herramientas necesarias para lograr esta escalabilidad de manera efectiva.
- Mayor fiabilidad: Al reducir el riesgo de errores e inconsistencias a través de la automatización y la estandarización de procesos, MLOps garantiza que los modelos de ML sean precisos y fiables una vez que están en producción.
- Colaboración mejorada: MLOps establece un marco común y un conjunto de herramientas que facilitan la colaboración efectiva entre científicos de datos, ingenieros de ML y equipos de operaciones. Esto ayuda a romper los silos organizacionales y a fomentar una cultura de responsabilidad compartida y comunicación fluida.
- Tiempo de comercialización más rápido: La agilización de todo el ciclo de vida del ML permite a las empresas desplegar sus modelos con mayor rapidez, lo que les confiere una ventaja competitiva en el mercado al poder capitalizar las oportunidades de la IA de forma más ágil.
- Gobernanza y cumplimiento: MLOps establece un proceso de desarrollo definido y escalable que garantiza la consistencia, la reproducibilidad y una gobernanza robusta a lo largo de todo el ciclo de vida del ML. Esto es crucial para cumplir con regulaciones y estándares éticos.
La analogía de una «cadena de montaje» para MLOps es particularmente ilustrativa de su valor central. Múltiples fuentes describen MLOps como la creación de una «cadena de montaje para construir y ejecutar modelos de aprendizaje automático» o como un proceso que «abarca todo el ciclo de desarrollo». Esta metáfora va más allá de la simple automatización; implica una estandarización rigurosa de los procesos, una reproducibilidad inherente y una eficiencia a escala, similar a cómo una línea de producción industrial garantiza una calidad de producto constante y un alto rendimiento. Esto no solo acelera el despliegue, sino que también reduce los errores y asegura una calidad predecible del modelo, lo cual es fundamental para la confianza y la adopción de la IA en el negocio. La estandarización de los flujos de trabajo, desde la ingesta de datos hasta el monitoreo, permite que los equipos colaboren de manera más efectiva, minimizando las fricciones y los malentendidos que a menudo surgen en proyectos de ML complejos.
El Ciclo de Vida de MLOps: De la Experimentación a la Producción
El ciclo de vida de MLOps es un proceso iterativo y continuo, fundamentalmente distinto de un enfoque lineal, que abarca varias etapas clave optimizadas para la producción y el mantenimiento a largo plazo de los modelos de IA. Este enfoque cíclico es crucial para garantizar que los modelos sigan siendo relevantes y precisos en un entorno de datos y negocios en constante cambio.
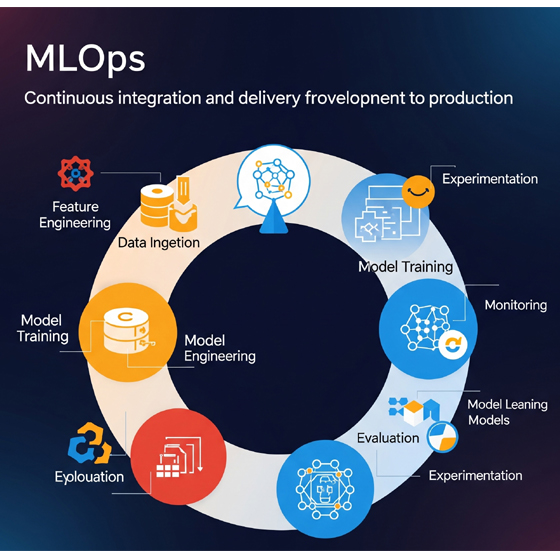
Fases del Ciclo de Vida de ML bajo MLOps
Las fases principales del ciclo de vida de ML bajo el enfoque MLOps son las siguientes:
- Definición del problema: Esta etapa inicial implica una comprensión profunda del problema empresarial que se busca resolver mediante el aprendizaje automático. Se establecen objetivos claros y se identifican los indicadores clave de rendimiento (KPIs) que servirán para medir el éxito del modelo en producción.
- Recopilación y preparación de datos: Esta fase es de vital importancia, ya que la calidad de los datos impacta directamente en el rendimiento del modelo. Incluye la ingesta de datos de diversas fuentes, su limpieza para eliminar inconsistencias y errores, su transformación para adaptarlos a los requisitos del modelo y su formateo adecuado para el entrenamiento. Tareas cruciales en esta etapa son la ingeniería de características (Feature Engineering) y el manejo de valores faltantes y atípicos.
- Desarrollo del modelo (Entrenamiento y Ajuste): Una vez que los datos están preparados, se procede a la selección del algoritmo o marco de trabajo más adecuado. El modelo se entrena utilizando los datos preparados, y su rendimiento se optimiza de forma iterativa mediante técnicas como el ajuste de hiperparámetros y la validación cruzada. El objetivo es desarrollar un modelo que resuelva eficazmente el problema planteado.
- Evaluación del modelo: Después del entrenamiento, es esencial evaluar el rendimiento del modelo para asegurar su efectividad. Esto implica medir diversas métricas, como precisión, recall, F1-score o área bajo la curva (AUC) para modelos de clasificación, o error cuadrático medio (RMSE), error absoluto medio (MAE) y R2 para modelos de regresión. Esta evaluación se realiza en conjuntos de datos de validación y prueba separados para garantizar una evaluación imparcial y evitar el sobreajuste.
- Despliegue del modelo: Una vez que el modelo ha sido entrenado y validado, se procede a su puesta en producción. Esto implica hacer que el modelo esté disponible para predicciones en tiempo real, integrándolo con aplicaciones y sistemas existentes para que los usuarios finales puedan interactuar con él.
- Monitoreo y mantenimiento del modelo: El monitoreo continuo es fundamental una vez que el modelo está en producción. Se vigila constantemente su rendimiento en escenarios del mundo real, detectando problemas como la deriva del modelo (model drift) o la deriva de datos (data drift), y activando alertas cuando se detectan anomalías o degradación del rendimiento.
- Reentrenamiento y actualización del modelo: Los modelos no son estáticos. A medida que los patrones de datos cambian o surgen nuevos requisitos empresariales, los modelos pueden volverse obsoletos. Esta fase implica actualizar los modelos con nuevos datos o algoritmos mejorados, a menudo de forma automatizada, para mantener su precisión y relevancia a lo largo del tiempo.
- Retiro y reemplazo del modelo: En última instancia, algunos modelos pueden necesitar ser retirados y reemplazados por versiones más nuevas y mejoradas que se adapten mejor a las condiciones cambiantes o a los objetivos empresariales.
Cómo MLOps Transforma Cada Fase
MLOps automatiza y agiliza cada una de estas fases, integrando principios de CI/CD para crear un flujo de trabajo cohesivo y eficiente. Esta transformación es lo que permite a las organizaciones escalar sus operaciones de IA de manera efectiva:
- Automatización de tareas repetitivas: Desde la preparación de datos hasta el entrenamiento y el despliegue, la automatización es un pilar central de MLOps. Esto reduce el esfuerzo manual y minimiza la probabilidad de errores humanos, lo que se traduce en una mayor eficiencia y consistencia en todo el ciclo de vida.
- Integración CI/CD: Las prácticas de integración y despliegue continuos son fundamentales en MLOps. Permiten la integración automatizada de cambios de código, el entrenamiento continuo de modelos y el despliegue rápido y fiable en producción.
- Versionado y trazabilidad: MLOps enfatiza el versionado riguroso de código, datos y modelos en cada etapa. Esto es crucial para garantizar la reproducibilidad de los experimentos, la trazabilidad de los resultados y la capacidad de revertir a versiones anteriores si es necesario.
- Uso de Feature Stores: Para la preparación de datos y la ingeniería de características, los feature stores centralizan y hacen reutilizables las características de ML. Esto no solo mejora la eficiencia al evitar la recreación de características, sino que también asegura la consistencia de los datos utilizados entre las fases de entrenamiento y de inferencia del modelo.
La dependencia central de MLOps en los datos, tanto en volumen como en calidad y diversidad (estructurados, semiestructurados y no estructurados), impulsa la necesidad de arquitecturas de almacenamiento y gestión de datos robustas y flexibles. Aquí es donde el concepto de Data Lakehouse se vuelve fundamental. Un Data Lakehouse combina la escalabilidad y el bajo costo de los Data Lakes (que almacenan datos en su formato nativo sin necesidad de transformación previa) con las características de gobernanza y rendimiento de los Data Warehouses (como la aplicación de esquemas, soporte para transacciones ACID y capacidades de consulta optimizadas). Esta arquitectura unificada permite establecer una «fuente única de verdad» para todos los datos de la organización. Esta unicidad es crucial para la reproducibilidad y la consistencia de los modelos de ML, ya que garantiza que todos los equipos trabajen con los mismos datos validados, lo que minimiza las discrepancias y mejora la fiabilidad de los resultados del modelo. Por lo tanto, la evolución hacia MLOps está intrínsecamente ligada a la adopción de arquitecturas de datos más avanzadas como el Lakehouse para soportar la complejidad y la escala de los datos de ML.
Además, la naturaleza iterativa y de bucle de retroalimentación continuo de MLOps es una característica distintiva que lo diferencia de un proceso lineal tradicional. Mientras que el desarrollo de software a menudo sigue un camino más directo hacia el despliegue, MLOps se concibe como un proceso «iterativo». La información obtenida del monitoreo y la optimización retroalimenta directamente el desarrollo del modelo, lo que conduce a una mejora continua. El concepto de «deriva del modelo» (model drift) y «deriva de datos» (data drift) es fundamental en este aspecto. Los modelos, una vez desplegados, no son estáticos; su rendimiento puede degradarse a medida que los datos de entrada cambian con el tiempo, o si la relación entre las características y el objetivo se modifica. Esta realidad operativa exige un «monitoreo continuo» para detectar la deriva y, crucialmente, un «reentrenamiento automatizado» para adaptar el modelo a las nuevas distribuciones de datos. Este bucle de retroalimentación constante es lo que distingue el ciclo de vida de MLOps de los ciclos de vida de software tradicionales, haciendo que el despliegue sea un punto de partida para un proceso de mejora y mantenimiento ininterrumpido.
Pilares Fundamentales de MLOps
La implementación exitosa de MLOps se sustenta en varios pilares fundamentales que garantizan la robustez, eficiencia y fiabilidad de los sistemas de IA en producción.
Reproducibilidad: Asegurando la Consistencia de Experimentos y Resultados
La reproducibilidad en MLOps se define como la capacidad de recrear de forma fiable los resultados de un experimento o flujo de trabajo de IA/ML. Esta capacidad es de vital importancia para validar hallazgos, depurar modelos y asegurar un comportamiento consistente en diferentes entornos y a lo largo del tiempo. La reproducibilidad es una piedra angular en cualquier empresa científica, y el aprendizaje automático no es una excepción. Asegura que los resultados no se deban al azar o a configuraciones ambientales específicas, lo que genera confianza en los modelos y los hace más fiables para el despliegue.
Los elementos clave para lograr la reproducibilidad incluyen:
- Versionado de datos, modelos y código: Es fundamental mantener un control de versiones riguroso de todos los artefactos del proyecto. Esto permite rastrear cada cambio, revertir a versiones anteriores si es necesario y asegurar la consistencia en todas las etapas del ciclo de vida del ML. El versionado de datos, en particular, es crucial para mantener la integridad y la reproducibilidad del análisis, permitiendo la trazabilidad de los resultados.
- Gestión de entornos y dependencias: Garantizar que el entorno de ejecución (versión de Python, librerías, dependencias) sea consistente es vital. Herramientas como Docker se utilizan para encapsular las dependencias y promover la consistencia y portabilidad del entorno. Esto asegura que el mismo modelo o aplicación pueda reconstruirse de forma idéntica en cualquier momento.
- Control de la aleatoriedad: Las tareas de IA/ML a menudo implican aleatoriedad en la inicialización del modelo, la mezcla de datos o la ejecución del algoritmo. Para lograr la reproducibilidad, es necesario controlar esta aleatoriedad fijando semillas aleatorias, lo que asegura que los generadores de números aleatorios produzcan la misma secuencia y, por lo tanto, conduzcan a resultados consistentes en ejecuciones diferentes.
- Plataformas de gestión de experimentos: Herramientas como MLflow Projects proporcionan un formato estándar para empaquetar código de ciencia de datos de manera reutilizable y reproducible. Estas plataformas ayudan a mantener registros detallados de las iteraciones del modelo, las configuraciones de hiperparámetros y los resultados de los experimentos, facilitando la comparación y la identificación de los enfoques más efectivos.
La relación entre la reproducibilidad y la confianza en los modelos de ML es simbiótica. Si un modelo no es reproducible, resulta casi imposible diagnosticar por qué su rendimiento se degrada en producción o por qué produce resultados inesperados. Esta falta de capacidad de depuración y verificación socava directamente la confianza en el modelo y, por extensión, en las decisiones empresariales basadas en él. La capacidad de «revertir a versiones anteriores» es una consecuencia directa de un buen versionado, lo que permite correcciones rápidas y el mantenimiento de la confianza en el sistema de IA. Por lo tanto, la reproducibilidad no es solo una buena práctica científica, sino un requisito operativo fundamental para la fiabilidad y la confianza en los sistemas de IA en producción.
Escalabilidad: Manejando Volúmenes Crecientes de Datos y Modelos
La escalabilidad se refiere a la capacidad de un sistema para manejar cargas crecientes y disminuir la carga, respondiendo rápidamente a los cambios en los requisitos de procesamiento. En el contexto de ML, esto significa escalar las aplicaciones para que puedan manejar cualquier cantidad de datos y realizar cómputos de manera rentable y rápida para millones de usuarios a nivel global. A medida que las organizaciones adoptan cada vez más modelos de ML, la capacidad de escalar estos modelos desde el prototipo hasta la producción se convierte en un desafío significativo.
Los desafíos comunes de escalabilidad incluyen la complejidad de los datos, la complejidad del modelo, la gestión de la infraestructura, la integración de sistemas y la colaboración entre equipos. Para abordar estos desafíos, se implementan diversas estrategias:
- Infraestructura escalable: La utilización de plataformas en la nube (como AWS, Azure y Google Cloud) es fundamental. Estas plataformas ofrecen soluciones de infraestructura escalables, incluyendo clústeres de autoescalado, servicios gestionados de Kubernetes y opciones de computación sin servidor, que pueden adaptarse dinámicamente a la demanda.
- Flujos de trabajo automatizados: La automatización de tareas repetitivas en el ciclo de vida del ML contribuye significativamente a la escalabilidad, ya que reduce el esfuerzo manual y permite procesar más cargas de trabajo con los mismos recursos.
- Contenerización y orquestación: El uso de contenedores (como Docker) crea entornos de ejecución consistentes y aislados, mientras que las herramientas de orquestación (como Kubernetes) gestionan estas aplicaciones contenerizadas para asegurar su escalabilidad y resiliencia en producción.
- Infraestructura como código (IaC): Las prácticas de IaC, mediante herramientas como Terraform o Ansible, automatizan y gestionan el aprovisionamiento y la configuración de la infraestructura. Esto garantiza la consistencia entre los entornos de desarrollo, prueba y producción, y soporta la escalabilidad al permitir la creación rápida y repetible de recursos.
Monitoreo Continuo: Vigilancia del Rendimiento y la Calidad del Modelo en Producción
El monitoreo continuo es un pilar fundamental de MLOps, que implica la vigilancia constante del rendimiento del modelo, la calidad de los datos y la salud de la infraestructura en producción. Su objetivo principal es la detección temprana y proactiva de problemas para una mejora continua del sistema de IA.
Un aspecto crítico del monitoreo es la detección de la deriva de datos y modelos (Data Drift, Concept Drift). Incluso el modelo más preciso puede deteriorarse con el tiempo a medida que los datos de entrada en producción se desvían de los datos con los que fue entrenado. Esta degradación del rendimiento se conoce como deriva del modelo (model drift), que se subdivide en:
- Deriva de datos (data drift): Se produce cuando la distribución de los datos de entrada cambia con el tiempo.
- Deriva de concepto (concept drift): Ocurre cuando la relación entre las entradas del modelo (características) y sus resultados (etiquetas) cambia. Herramientas especializadas como Evidently AI y Fiddler AI están diseñadas para ayudar a detectar estas derivas, proporcionando informes interactivos y alertas.
Para un monitoreo efectivo, se utilizan diversas métricas clave:
- Para modelos de clasificación: Precisión, recall, F1-score, ROC-AUC, matriz de confusión y log loss.
- Para modelos de regresión: Error cuadrático medio (RMSE), error absoluto medio (MAE), error porcentual absoluto medio (MAPE) y coeficiente de determinación (R2).
Se configuran sistemas de alerta y reentrenamiento automatizado para notificar a los equipos sobre anomalías o degradación del rendimiento. Estas alertas pueden desencadenar un reentrenamiento automatizado del modelo , asegurando que el modelo se adapte a las nuevas distribuciones de datos y mantenga su precisión.
La deriva del modelo representa un desafío persistente que transforma el despliegue de ML de un evento único a un proceso continuo. La investigación indica que «incluso el modelo más preciso se degradará con el tiempo a medida que los datos de entrada se desvíen de los datos de entrenamiento». Esto significa que un modelo de ML desplegado no es una solución estática; está sujeto a cambios en el entorno del mundo real. Esta realidad operativa exige un «monitoreo continuo» para detectar la deriva y, crucialmente, un «reentrenamiento automatizado» para adaptar el modelo a las nuevas distribuciones de datos. Este bucle de retroalimentación constante es lo que distingue el ciclo de vida de MLOps de los ciclos de vida de software tradicionales, haciendo que el despliegue sea un punto de partida para un proceso de mejora y mantenimiento ininterrumpido. La capacidad de detectar y responder a la deriva es lo que permite a las organizaciones mantener la relevancia y la precisión de sus sistemas de IA a largo plazo, garantizando que sigan proporcionando valor de negocio.
Gestión del Ciclo de Vida y CI/CD: Automatización Integral y Entrega Continua
MLOps automatiza todo el ciclo de vida del desarrollo de ML, desde la preparación de datos y el entrenamiento del modelo hasta las pruebas y el despliegue. Esta automatización integral es clave para la eficiencia y la fiabilidad.
La disciplina de MLOps incorpora la metodología de integración continua y entrega/despliegue continuo (CI/CD) de DevOps para crear una «cadena de montaje» para cada paso en la creación de un producto de ML. Esto implica pruebas automatizadas, integración continua de cambios de código y modelos, y despliegue continuo en producción. Los pipelines de CI/CD en MLOps agilizan los ciclos de entrega, permitiendo a los equipos introducir innovaciones en el mercado más rápidamente y con mayor confianza en la fiabilidad de sus soluciones de ML. La automatización de estas fases reduce significativamente las posibilidades de error humano, mejorando la fiabilidad general de los sistemas de ML.
Las herramientas y estrategias clave para CI/CD y el despliegue incluyen:
- Pipelines de despliegue: Herramientas como Jenkins, GitLab CI/CD y CircleCI gestionan estos pipelines y automatizan el proceso de despliegue, asegurando que los modelos se desplieguen de manera fiable y consistente.
- Contenerización: Docker y Kubernetes proporcionan la infraestructura para contenerizar modelos de ML. Esto encapsula el modelo y sus dependencias en un paquete portátil, facilitando el despliegue en diversos entornos de nube y garantizando la consistencia del entorno de ejecución.
- Estrategias de despliegue: Para minimizar los riesgos en producción, se emplean estrategias avanzadas como el despliegue en sombra (Shadow Deployment) y el despliegue Canary (Canary Deployment). El despliegue en sombra implica ejecutar el nuevo modelo junto con el existente sin afectar el tráfico de producción, permitiendo una comparación de rendimientos en un entorno real. El despliegue Canary, por otro lado, introduce el nuevo modelo a un pequeño subconjunto de usuarios antes de un despliegue completo, lo que permite monitorear su comportamiento y detectar problemas antes de que afecten a toda la base de usuarios.
Colaboración y Gobernanza: Uniendo Equipos y Garantizando la Ética y el Cumplimiento
MLOps es intrínsecamente una función colaborativa. Fomenta la colaboración activa entre científicos de datos, ingenieros de ML y equipos de TI/operaciones, proporcionando un marco común y un conjunto de herramientas. Esto reduce los silos organizacionales y las posibles fallas de comunicación, asegurando que todos los involucrados trabajen juntos de manera efectiva y comprendan el proceso completo. Este enfoque colaborativo cierra la brecha entre la ciencia de datos y el desarrollo de software, aprovechando la automatización y CI/CD para optimizar el despliegue, monitoreo y mantenimiento de los sistemas de ML.
En cuanto a la gobernanza, las prácticas de MLOps abordan el cumplimiento normativo y las directrices éticas, garantizando el acceso seguro, la privacidad de los datos y la seguridad del modelo a lo largo de todo el ciclo de vida del ML. Esto implica la creación y aplicación de políticas y directrices para el desarrollo, despliegue y uso responsable de los modelos de ML, considerando la equidad, la privacidad y el cumplimiento normativo. Establecer una estrategia robusta de gobernanza de ML ayuda a mitigar riesgos, proteger contra el uso indebido de la tecnología y alinear las iniciativas de ML con estándares éticos y legales más amplios.
Los aspectos clave de la gobernanza en MLOps incluyen:
- Validación del modelo: Asegurar que el modelo de ML cumpla con los estándares de rendimiento y calidad deseados.
- Equidad del modelo: Garantizar que el modelo de ML no exhiba sesgos ni discriminación. Esto es crucial para la IA responsable.
- Interpretabilidad del modelo: Asegurar que el modelo de ML sea comprensible y explicable, lo que es vital para la confianza y la auditoría, especialmente en campos regulados.
- Seguridad del modelo: Proteger el modelo de ML contra ataques y accesos no autorizados.
La gobernanza también se extiende a la gestión de metadatos, el linaje de datos y el control de acceso.
La arquitectura Lakehouse emerge como un habilitador fundamental para MLOps, especialmente en la gestión y gobernanza de datos. La investigación detalla extensamente los Data Lakes y Lakehouses. La conexión radica en que MLOps requiere una infraestructura de datos robusta y flexible para manejar la diversidad y el volumen de datos de ML. Los Lakehouses combinan las ventajas de los Data Lakes (almacenamiento de bajo costo, escalabilidad, flexibilidad para datos estructurados, semiestructurados y no estructurados) con las capacidades de los Data Warehouses (aplicación de esquemas, transacciones ACID, gobernanza de datos y rendimiento para consultas analíticas). Esta arquitectura unificada aborda directamente desafíos de MLOps como la calidad y gestión de datos , la necesidad de una «fuente única de verdad» para la reproducibilidad, y la capacidad de soportar diversas cargas de trabajo de IA/ML y BI en la misma plataforma. La capacidad de un Lakehouse para aplicar gobernanza a datos crudos y refinados, y para soportar transacciones ACID, es fundamental para la integridad de los datos en un entorno MLOps, donde la consistencia y la fiabilidad son primordiales. Por lo tanto, la adopción de un Lakehouse es una estrategia arquitectónica clave para construir una base sólida y eficiente para las operaciones de MLOps.
Herramientas Clave en el Ecosistema MLOps
El ecosistema de MLOps es vasto y en constante evolución, ofreciendo una amplia gama de herramientas que facilitan la implementación de sus principios. Estas herramientas pueden clasificarse en plataformas integrales o soluciones específicas por categoría.
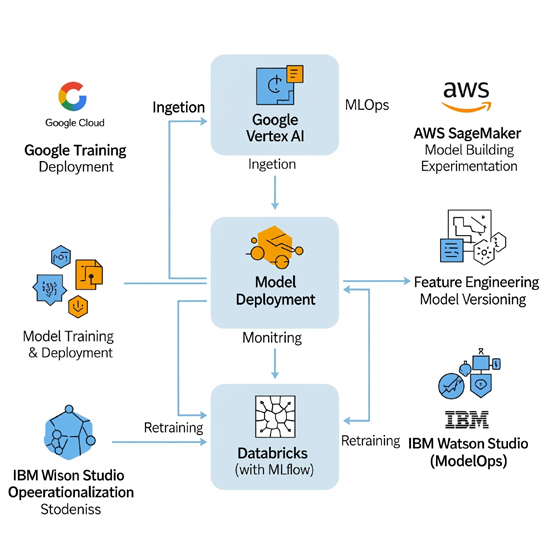
Plataformas MLOps Integrales
Estas plataformas proporcionan una solución de extremo a extremo para gestionar el ciclo de vida del ML, a menudo con profundas integraciones dentro de un ecosistema de nube particular.
- Google Cloud Vertex AI: Es la plataforma unificada de Google Cloud para construir, entrenar, probar, monitorear y desplegar modelos de ML y IA. Ofrece entrenamiento personalizado, acceso a un vasto Model Garden con más de 150 modelos (incluidos modelos fundacionales como Gemini), Vertex AI Pipelines para la automatización de flujos de trabajo, Vertex ML Metadata para el seguimiento de artefactos y parámetros, Vertex AI Model Registry para la gestión de versiones de modelos y Vertex AI Model Monitoring para la detección de deriva. Se integra con servicios de Google Cloud como BigLake para la gestión de datos.
- AWS SageMaker: Una suite integral de herramientas MLOps de Amazon Web Services, diseñada para agilizar el ciclo de vida del ML. Incluye SageMaker Projects para CI/CD, SageMaker Pipelines para la creación y gestión de flujos de trabajo de ML (basados en DAGs), y SageMaker Model Registry para centralizar el seguimiento y despliegue de modelos. Se integra con GitHub Actions y otros servicios de AWS para la automatización de pipelines. SageMaker Lakehouse unifica el acceso a datos en S3 y Redshift para aplicaciones de IA/ML.
- Azure Machine Learning: Plataforma basada en la nube de Microsoft para construir, entrenar y desplegar modelos de ML a escala. Ofrece capacidades para la colaboración entre equipos (a través de registros centralizados), automatización de procesos (CI/CD con Azure DevOps y GitHub Actions), seguimiento de experimentos, monitoreo de rendimiento y gobernanza de activos. Permite la creación de pipelines escalables y reproducibles con control de versiones y monitoreo de datos.
- Databricks (con MLflow): Construido sobre Apache Spark, Databricks ofrece una arquitectura lakehouse unificada que combina lo mejor de los data lakes y data warehouses. Utiliza Delta Lake como capa de almacenamiento optimizada con soporte para transacciones ACID y aplicación de esquemas, y Unity Catalog para una gobernanza unificada de datos e IA. MLflow es una herramienta de código abierto fundamental para la gestión del ciclo de vida de ML, incluyendo el seguimiento de experimentos, la reproducibilidad, el despliegue y el registro de modelos.
- IBM Watson Studio (ModelOps): Plataforma colaborativa que permite a científicos de datos, desarrolladores y analistas construir, ejecutar y gestionar modelos de IA. Se centra en ModelOps, la operacionalización de modelos, para automatizar la gestión del ciclo de vida de la IA, acelerar el tiempo de valor y garantizar la gobernanza. Integra CI/CD y ofrece monitoreo de sesgos y deriva del modelo.
Herramientas por Categoría Específica
Más allá de las plataformas integrales, existe un rico ecosistema de herramientas especializadas que pueden ser utilizadas individualmente o integradas para construir una pila MLOps personalizada, adaptándose a necesidades específicas o a infraestructuras existentes.
Versionado de Datos y Modelos: El versionado es crucial para la reproducibilidad y la trazabilidad en MLOps, permitiendo a los equipos rastrear cambios y recrear experimentos.
- DVC (Data Version Control): Herramienta de código abierto que se integra con Git para versionar código, datos, modelos, metadatos y pipelines. Facilita la gestión de conjuntos de datos y modelos de ML, y ayuda a responder preguntas sobre cómo se construyó un modelo.
- MLflow: Aunque es una plataforma más amplia, MLflow es ampliamente reconocido por su componente de seguimiento de experimentos y registro de modelos, que permite versionar y gestionar modelos a lo largo de su ciclo de vida.
- lakeFS: Plataforma de gestión de data lakes de código abierto que transforma el almacenamiento de objetos en un repositorio tipo Git, permitiendo operaciones como branch, commit y merge sobre los datos a escala de exabytes. Esto es particularmente útil para el versionado de grandes volúmenes de datos.
- Pachyderm: Una herramienta para pipelines de datos automatizados y con control de versiones en Kubernetes, que proporciona seguimiento de linaje de datos y versionado de datos a medida que se procesan.
- Weights & Biases: Una plataforma para registrar experimentos, versionar datos y modelos, optimizar hiperparámetros y gestionar modelos, ofreciendo una visión integral de los artefactos de ML.
Orquestación de Flujos de Trabajo: Estas herramientas automatizan, programan y monitorean los flujos de trabajo de ML, asegurando que cada paso se ejecute en el orden correcto y sin problemas.
- Apache Airflow: Una herramienta veterana y flexible para automatizar, programar y monitorear flujos de trabajo, utilizada a menudo para pipelines ETL y ML. Aunque no fue construida exclusivamente para ML, su flexibilidad la hace una opción popular.
- Kubeflow: Diseñado específicamente para desplegar modelos de ML en Kubernetes, facilita la construcción y gestión de pipelines de ML en la nube. Es ideal para equipos con fuertes habilidades en DevOps y que operan en entornos nativos de la nube.
- Prefect: Una herramienta de orquestación de código abierto para monitorear, coordinar y orquestar operaciones en pipelines de ML, conocida por su interfaz limpia y fácil de usar. Ofrece una curva de aprendizaje más suave en comparación con otras herramientas.
- Dagster: Plataforma de orquestación que enfatiza la construcción de flujos de trabajo limpios, testeables y fiables con comprobaciones de tipo y validación de datos integradas.
- Metaflow: Desarrollado por Netflix, permite a los científicos de datos centrarse en el modelado, manejando el versionado, la escalabilidad y el despliegue con mínima intervención de DevOps. Es muy amigable con Python.
Monitoreo de Modelos: El monitoreo continuo es vital para detectar la deriva del modelo, la degradación del rendimiento y otros problemas en producción.
- Evidently AI: Librería Python de código abierto para monitorear modelos de ML a lo largo del desarrollo, validación y producción, evaluando la calidad de datos y modelos, la deriva y el rendimiento.
- Fiddler AI: Herramienta de monitoreo de modelos de ML con una interfaz fácil de usar, que permite explicar y depurar predicciones, evaluar el comportamiento del modelo y rastrear el rendimiento.
- Prometheus y Grafana: Herramientas populares para monitorear métricas de rendimiento de infraestructura y aplicaciones, incluyendo sistemas ML. Prometheus recopila métricas y Grafana las visualiza en paneles interactivos, permitiendo la detección de anomalías y la configuración de alertas.
Despliegue y Servido de Modelos: Estas herramientas facilitan la puesta en producción de modelos entrenados y su disponibilidad para inferencia en tiempo real.
- Kubernetes: Un sistema de orquestación de contenedores que ayuda a gestionar y ejecutar modelos dentro de contenedores. Permite escalar automáticamente los recursos y garantizar la resiliencia en producción.
- TensorFlow Serving: Un sistema diseñado específicamente para ejecutar modelos de TensorFlow en producción. Facilita el despliegue de modelos como pequeños servicios que pueden manejar muchas solicitudes a la vez y escalar para soportar más usuarios.
- BentoML: Una utilidad basada en Python para desplegar y gestionar APIs en producción, simplificando y acelerando el despliegue de aplicaciones de ML. Incluye aceleración de hardware y optimizaciones para escalabilidad.
Conclusión: El Futuro de la IA con MLOps
MLOps no es simplemente una tendencia, sino una disciplina indispensable para la madurez y el éxito a largo plazo de los proyectos de IA en el mundo real. Transforma el desarrollo de modelos de ML de un arte experimental a una ingeniería robusta y operacionalizable. La creciente integración de la IA en las operaciones empresariales ha hecho que la adopción de MLOps sea una necesidad, ya que las prácticas manuales son insuficientes para los requisitos de fiabilidad, consistencia y escalabilidad de los sistemas de IA en producción.
Al automatizar, estandarizar y monitorear cada fase del ciclo de vida del ML, MLOps garantiza una mayor eficiencia, escalabilidad, fiabilidad y una colaboración fluida entre equipos. La capacidad de reproducir experimentos, manejar volúmenes crecientes de datos y modelos, y monitorear continuamente el rendimiento en producción son pilares que aseguran la calidad y la relevancia de los modelos de IA a lo largo del tiempo. La persistencia de desafíos como la deriva del modelo subraya que el despliegue de ML es un proceso continuo, no un evento único, requiriendo un monitoreo constante y un reentrenamiento automatizado para mantener la precisión.
La evolución de las arquitecturas de datos, como el Lakehouse, y la aparición de un ecosistema diverso de herramientas (desde plataformas integrales hasta soluciones específicas por categoría) subrayan el compromiso de la industria con la operacionalización de la IA. La adopción de arquitecturas Lakehouse proporciona una base de datos unificada y gobernada, crucial para la reproducibilidad y la consistencia de los datos en MLOps, permitiendo que los equipos trabajen desde una «fuente única de verdad».
En última instancia, MLOps permite a las organizaciones no solo construir modelos de IA, sino también mantenerlos relevantes, precisos y seguros en entornos de producción dinámicos. Esto desbloquea todo el potencial de la inteligencia artificial para impulsar la innovación y generar un valor empresarial sostenible, transformando la promesa de la IA en una realidad operativa.
——————————————
Fuentes: