
La era digital ha sido testigo de una explosión sin precedentes en el volumen, la velocidad y la variedad de datos generados por las organizaciones. Desde transacciones estructuradas hasta feeds de redes sociales, datos de sensores IoT y documentos no estructurados, la necesidad de almacenar y analizar esta información de manera eficiente se ha vuelto crítica para la toma de decisiones empresariales. Este crecimiento exponencial de datos de diversas fuentes ha impulsado la búsqueda de soluciones de almacenamiento y procesamiento más flexibles y escalables.
Históricamente, los Data Warehouses (Almacenes de Datos) han sido el pilar para el análisis de datos estructurados y el Business Intelligence (BI). Estos sistemas están optimizados para el envío y recepción de datos a gran velocidad y son ideales para explotar directamente datos con herramientas de BI. Sin embargo, su rigidez inherente, que requiere que los datos sean transformados y organizados antes de ser almacenados, y su alto costo para manejar volúmenes masivos de datos brutos y heterogéneos, limitaron su capacidad para satisfacer las nuevas demandas de análisis. La introducción de nuevas fuentes de datos también implicaba un trabajo significativo.
Para superar estas limitaciones, surgieron los Data Lakes, diseñados para almacenar datos en su forma original, ofreciendo una flexibilidad y rentabilidad sin precedentes. Esta capacidad de almacenar datos en su forma original permite a las organizaciones conservar la integridad de los datos y adaptarse fácilmente a nuevos requisitos de análisis.
A pesar de sus ventajas, los Data Lakes introdujeron sus propios desafíos, como la dificultad en la gobernanza y la calidad de los datos. Esta situación llevó a la evolución hacia la arquitectura Data Lakehouse, que busca combinar lo mejor de los Data Lakes y los Data Warehouses para una solución más completa y unificada. La trayectoria de estas arquitecturas de datos revela una presión evolutiva constante. Cada solución, si bien aborda problemas previos, introduce nuevas complejidades o limitaciones. Los Data Warehouses no podían con la diversidad y el volumen de datos brutos, lo que llevó a los Data Lakes. Los Data Lakes, aunque flexibles y económicos, carecían de la estructura y la gobernanza necesarias para la fiabilidad de los datos. Esta sucesión de soluciones y problemas subraya la búsqueda continua de una plataforma que pueda manejar todos los tipos de datos para todos los tipos de análisis (tanto BI como Machine Learning) de manera eficiente y confiable. La evolución arquitectónica refleja la necesidad de las organizaciones de una utilización más holística de sus datos, eliminando la dependencia de sistemas aislados y las complejidades de integración.
Que es un Data Lake?

Un Data Lake, o Lago de Datos, es un concepto fundamental en la gestión de Big Data, diseñado para almacenar grandes volúmenes de información en su estado más puro y original. Es un repositorio centralizado que permite almacenar, compartir, gobernar y descubrir grandes cantidades de datos estructurados, semiestructurados y no estructurados de una organización a cualquier escala. Su propósito principal es almacenar copias en bruto de los datos de una organización para su explotación en procesos de análisis, reporting y Machine Learning, permitiendo extraer valor sin restricciones de formato. La capacidad de almacenar datos en su forma original permite a las organizaciones conservar la integridad de los datos y adaptarse fácilmente a nuevos requisitos de análisis.
Los principios operativos de un Data Lake se centran en la flexibilidad y la escalabilidad. Una característica distintiva es el enfoque «schema-on-read». A diferencia de los Data Warehouses, que requieren que los datos sean transformados y organizados antes de ser almacenados, un Data Lake permite la ingesta de datos sin procesar de diversas fuentes. Los datos se guardan tal como se generan, y el esquema se aplica en el momento de la lectura o el análisis, lo que proporciona una flexibilidad máxima para futuros análisis que no se hayan definido previamente. Esta flexibilidad se extiende a la capacidad de manejar una amplia variedad de tipos de datos, incluyendo datos estructurados (de bases de datos transaccionales), semiestructurados (como JSON, XML, logs) y no estructurados (imágenes, videos, documentos, feeds de redes sociales). Otro principio clave es la separación de los recursos de cómputo y almacenamiento, lo que permite escalarlos de forma independiente según las necesidades, optimizando costos y rendimiento.
La arquitectura típica de un Data Lake se compone de varias capas clave:
- Capa de Ingesta: Sirve como punto de entrada para los datos, recolectando e integrando información de diversas fuentes como dispositivos IoT, bases de datos transaccionales y APIs. Soporta ingesta por lotes (batch) y streaming en tiempo real.
- Capa de Almacenamiento y Persistencia: Es la base del Data Lake, donde los datos se almacenan en su formato nativo. Comúnmente utiliza sistemas de almacenamiento distribuido como Hadoop Distributed File System (HDFS) o almacenamiento de objetos en la nube (ej., Amazon S3, Azure Data Lake Storage, Google Cloud Storage) debido a su escalabilidad y rentabilidad.
- Capa de Procesamiento y Análisis: En esta etapa, los datos brutos se preparan para el análisis. Se realizan transformaciones como limpieza, filtrado, unión y enriquecimiento. Motores como Apache Spark o Hadoop MapReduce son comunes aquí, y es donde el «schema-on-read» entra en juego.
- Capa de Gobernanza y Catálogo de Metadatos: Aunque a menudo es un desafío en los Data Lakes puros, es crucial para la calidad, seguridad y cumplimiento de los datos. Implica la gestión de metadatos (organizar y etiquetar datos para facilitar su búsqueda), control de acceso y monitoreo de la calidad.
La capacidad de ingesta de datos sin un esquema o propósito predefinido, si bien confiere una flexibilidad sin igual, también puede generar una paradoja. Si no se complementa con una capa de gobernanza robusta (que en Data Lakes puros a menudo es externa o una adición posterior), esta flexibilidad puede conducir a la desorganización y la falta de confianza en los datos, transformando el Data Lake en un «data swamp» (pantano de datos) lleno de información irrelevante o inutilizable. Esto resalta un desafío operativo crítico: la flexibilidad técnica de almacenar cualquier cosa debe ser equilibrada con la disciplina organizacional de saber qué se almacena y por qué. El éxito de un Data Lake depende en gran medida de prácticas de gobernanza de datos sólidas, que no están intrínsecamente integradas en su mecanismo de almacenamiento central.
Además, aunque los Data Lakes son fundamentales para Machine Learning y análisis avanzado y capaces de manejar datos en tiempo real , a menudo dependen de motores de procesamiento externos como Apache Spark o Hadoop. El rendimiento de las consultas puede ser potencialmente más lento para datos estructurados en comparación con los Data Warehouses. Esto sugiere que un Data Lake, por sí mismo, no es una solución completa de extremo a extremo para todas las necesidades analíticas. En cambio, actúa como una base o habilitador altamente flexible y rentable sobre la cual deben construirse otras herramientas y capas especializadas para procesamiento, BI, ML y gobernanza. Esto implica un mayor esfuerzo de integración y potencialmente un ecosistema más complejo de gestionar en comparación con una solución más integrada.
Que es un Data Lakehouse?
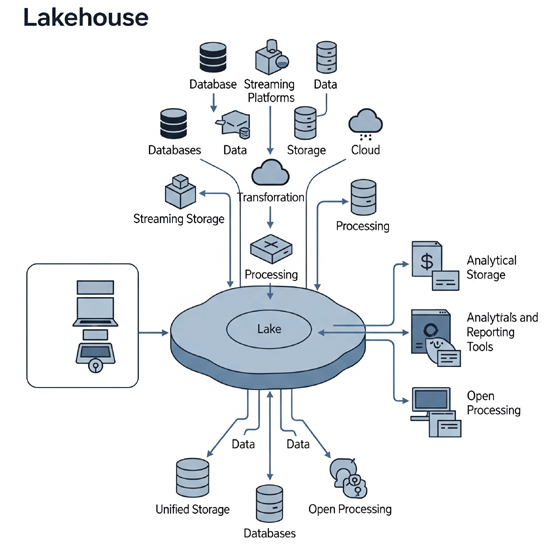
El Data Lakehouse representa la siguiente evolución en las arquitecturas de datos, buscando cerrar la brecha entre la flexibilidad de los Data Lakes y la fiabilidad y el rendimiento de los Data Warehouses. Es una arquitectura de datos híbrida que combina los beneficios de los Data Lakes (almacenamiento flexible y de bajo costo para grandes volúmenes de datos brutos de todo tipo) y los Data Warehouses (capacidades de gestión de datos, estructura y rendimiento para análisis). Su objetivo es superar las limitaciones de ambos, ofreciendo una solución unificada e integrada para gestionar y analizar datos a escala, soportando tanto Machine Learning como Inteligencia de Negocios en una sola plataforma.
Los principios operativos de un Data Lakehouse se basan en la unificación de almacenamiento y las capacidades de Data Warehouse. Utiliza el mismo almacenamiento de objetos en la nube de bajo costo que los Data Lakes para almacenar datos en bruto, pero integra capas de metadatos (a menudo a través de formatos de tabla abiertos como Delta Lake, Apache Iceberg o Apache Hudi) para proporcionar capacidades similares a las de un Data Warehouse. Una de las características más importantes es el soporte para transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad). Las Lakehouses garantizan la fiabilidad e integridad de los datos a través de estas transacciones, permitiendo gestionar actualizaciones y eliminaciones con confianza, un nivel de integridad de datos que antes era exclusivo de los Data Warehouses tradicionales.
A diferencia de los Data Lakes puros, las Lakehouses aplican esquemas para mantener la calidad de los datos, lo que facilita su consulta y análisis, y previene inconsistencias. Este enfoque puede ser en la ingesta o en la escritura de datos («schema-on-write»). La gestión unificada de metadatos es otro pilar fundamental; las Lakehouses recopilan y almacenan metadatos enriquecidos utilizando formatos de tabla modernos, lo que mejora el rendimiento de las consultas, la gobernanza y la capacidad de «viaje en el tiempo» (time travel) para ver versiones anteriores de los datos. Además, están diseñadas para procesar datos en tiempo real, lo que permite casos de uso como análisis en tiempo real e información inmediata, mejorando la capacidad de respuesta de las organizaciones. Finalmente, mantienen la característica fundamental de los Data Lakes de separación de almacenamiento y cómputo, permitiendo escalar los recursos de forma independiente y optimizar costos.
La arquitectura de un Data Lakehouse se estructura en las siguientes capas:
- Capa de Almacenamiento (Storage Layer): Es la capa del Data Lake subyacente, generalmente un almacén de objetos de bajo costo (ej., Amazon S3, Azure Data Lake Storage, Google Cloud Storage) para todos los conjuntos de datos sin procesar (estructurados, no estructurados, semiestructurados). Está desacoplada de los recursos de cómputo.
- Capa de Etapa de Pruebas/Metadatos (Staging/Metadata Layer): Se sitúa sobre la capa de almacenamiento del Data Lake. Proporciona un catálogo detallado de los objetos de datos, permitiendo aplicar características de gestión de datos como la aplicación de esquemas, propiedades ACID, indexación, caché y control de acceso. Tecnologías clave en esta capa incluyen Delta Lake, Apache Iceberg y Apache Hudi.
- Capa Semántica/Consumo (Semantic Layer): Es la capa superior que expone los datos para su uso. Aquí, los usuarios pueden emplear aplicaciones cliente y herramientas de análisis (Business Intelligence, Machine Learning, SQL Analytics) para acceder y aprovechar los datos para experimentación, informes y toma de decisiones empresariales.
La innovación central del Lakehouse reside en la integración de capas de metadatos sofisticadas, a menudo utilizando formatos de tabla abiertos como Apache Iceberg o Delta Lake, directamente sobre el almacenamiento de objetos de bajo costo. Este desarrollo transforma un Data Lake que antes era un simple repositorio de almacenamiento en un sistema «inteligente». Al añadir esta capa de metadatos, el Data Lake adquiere capacidades que antes eran exclusivas de los Data Warehouses, como las transacciones ACID y la aplicación de esquemas, todo ello sin necesidad de mover los datos a un sistema separado. Esta capacidad de infundir estructura y fiabilidad directamente en el lago de datos es lo que permite la unificación de las cargas de trabajo de BI y Machine Learning en una única plataforma, simplificando la arquitectura de datos y optimizando los costos.
Data Lake Vs Lakehouse: Análisis comparativo
La evolución de las arquitecturas de datos ha llevado a la convergencia de conceptos, y la distinción entre Data Lakes y Data Lakehouses es fundamental para comprender las capacidades modernas de gestión de datos.
- Organización de Datos y Rendimiento de Consultas:
- Un Data Lake almacena datos en su formato crudo, aplicando un enfoque de «schema-on-read». Esto significa que el esquema se define en el momento de la consulta, no en la ingesta, lo que ofrece una flexibilidad considerable para manejar grandes volúmenes de datos heterogéneos (estructurados, semiestructurados y no estructurados). Sin embargo, esta flexibilidad puede tener un costo en el rendimiento. Los Data Lakes tradicionalmente dependen de motores de procesamiento externos como Apache Spark o Hadoop para el análisis, lo que puede ralentizar el rendimiento de las consultas y requerir el uso de herramientas adicionales. Además, un Data Lake no soporta transacciones concurrentes, lo que puede llevar a inconsistencias o problemas de integridad de los datos cuando múltiples usuarios intentan acceder o modificar datos simultáneamente.
- En contraste, un Data Lakehouse combina la flexibilidad de los Data Lakes con la gestión estructurada de los Data Warehouses. Los Lakehouses aplican un «schema-on-write» o permiten la evolución de esquemas, lo que significa que los datos se pueden almacenar con un esquema predefinido, facilitando la integración y el análisis. Se integran con motores de procesamiento de datos para permitir análisis eficientes en tiempo real y consultas interactivas. Crucialmente, la arquitectura del Data Lakehouse incorpora soporte para transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) y versionado, lo que permite que múltiples usuarios o aplicaciones interactúen con los datos concurrentemente sin comprometer la integridad y consistencia de los datos. Esto optimiza el rendimiento de las consultas con indexación y permite un análisis avanzado de los datos estructurados dentro del Lakehouse.
- Escalabilidad y Costo:
- Tanto los Data Lakes como los Data Lakehouses son altamente escalables, permitiendo manejar volúmenes crecientes de datos al añadir más nodos de almacenamiento y procesamiento. Ambos son soluciones rentables, con la mayoría de los proveedores de nube ofreciendo modelos de pago por uso. Sin embargo, un Data Lakehouse puede reducir los costos aún más al minimizar el movimiento y la duplicación de datos, ya que unifica las capacidades de Data Lake y Data Warehouse en una sola plataforma.
- Calidad de Datos y Gobernanza:
- La calidad de los datos en un Data Lake a menudo se basa en la validación manual, y estos sistemas carecen de una gobernanza de datos centralizada, lo que dificulta el mantenimiento de la consistencia y seguridad. Sin controles adecuados, un Data Lake puede volverse desordenado e inmanejable, llevando a problemas de integridad de datos y al riesgo de convertirse en un «data swamp».
- Los Data Lakehouses, por otro lado, priorizan la gobernanza y tienen procesos de calidad de datos incorporados. La aplicación de esquemas facilita el mantenimiento de los estándares de datos y garantiza el cumplimiento durante la ingesta, lo que resulta en una consistencia, precisión y fiabilidad de los datos significativamente mejoradas.
Beneficios clave del Data Lakehouse sobre el Data Lake
La arquitectura Lakehouse ofrece una serie de ventajas significativas que la posicionan como una evolución superior para muchas organizaciones:
- Acceso Democratizado a los Datos: Los Data Lakehouses hacen que los datos sean más accesibles a diversos perfiles de usuario dentro de una organización, no solo a los ingenieros de datos. Esto significa que los analistas de negocio, científicos de datos y otros usuarios pueden interactuar directamente con los datos, sin las barreras que a menudo presentaban los Data Lakes puros o la necesidad de un costoso Data Warehouse separado.
- Reducción de la Complejidad de Gestión: Al introducir una capa de gobernanza mejorada entre los datos crudos y los datos consumibles, los Data Lakehouses simplifican la gestión de datos. Esto permite un estilo de gestión más parecido al de un Data Warehouse o una base de datos, pero con los beneficios de costo inherentes a la tecnología de Data Lake.
- Cumplimiento ACID y Soporte Transaccional: Una de las diferencias más cruciales es la capacidad de los Lakehouses para ofrecer cumplimiento ACID y un mayor soporte para datos transaccionales. Esto es vital para industrias y casos de uso donde la precisión y la integridad de los datos son primordiales, permitiendo potencialmente a las organizaciones consolidar sistemas que antes requerían plataformas separadas.
- Actualizaciones y Evolución de Esquemas Mejoradas: Los formatos de tabla modernos (como Apache Iceberg, Delta Lake o Apache Hudi) que subyacen a los Lakehouses permiten una evolución de esquemas y una gestión de actualizaciones y eliminaciones de datos mucho más eficientes. Esto supera una limitación significativa de los Data Lakes tradicionales, que a menudo luchaban con la mutabilidad de los datos.
- Menor Dependencia de Hive Metastore: Los Lakehouses utilizan formatos de tabla modernos que requieren menos operaciones en comparación con tecnologías más antiguas como Hive, ofreciendo un rendimiento superior.
- Operacionalización del Lago: Los Data Lakehouses proporcionan un soporte significativamente mejor para sistemas transaccionales que los Data Lakes tradicionales, gracias a su manejo único de metadatos. Esto permite a las organizaciones construir análisis de negocio basados en datos actualizados en tiempo real, mejorando la fiabilidad y el valor de la información derivada.
- Reducción/Eliminación de la Necesidad de Data Warehouses: Históricamente, las limitaciones de los Data Lakes obligaban a las organizaciones a operar un costoso Data Warehouse junto a ellos. Con su funcionalidad ampliada, el Data Lakehouse ahora puede reducir o incluso eliminar la necesidad de un Data Warehouse separado, consolidando la pila de datos.
- Mejora del Rendimiento: Los Lakehouses construidos sobre formatos de tabla modernos como Iceberg son más performantes que los Data Lakes tradicionales, con un rendimiento comparable al de los Data Warehouses. Esto se traduce en ahorros de tiempo, esfuerzo y costos.
La arquitectura Lakehouse actúa como un puente y un catalizador en la evolución de la gestión de datos. Al incorporar capacidades de Data Warehouse directamente en el Data Lake, crea una plataforma unificada que puede manejar cargas de trabajo diversas, desde el Business Intelligence tradicional hasta la analítica avanzada y el Machine Learning. Esta convergencia no solo simplifica la pila tecnológica, sino que también democratiza el acceso a los datos y acelera el tiempo para obtener información valiosa, impulsando una utilización más amplia de los datos en toda la organización.
Proveedores de nube y sus productos Lakehouse
La adopción de la arquitectura Data Lakehouse ha llevado a los principales proveedores de servicios en la nube a desarrollar y ofrecer soluciones robustas que facilitan su implementación.
Amazon Web Services (AWS): AWS ofrece Amazon SageMaker Lakehouse como su solución principal. Este servicio unifica todos los datos a través de los Data Lakes de Amazon Simple Storage Service (Amazon S3), incluyendo S3 Tables, y los Data Warehouses de Amazon Redshift. El objetivo es permitir la construcción de potentes aplicaciones de análisis y Machine Learning/Inteligencia Artificial (AI/ML) sobre una única copia de los datos. SageMaker Lakehouse proporciona la flexibilidad de acceder y consultar datos in-situ con todas las herramientas y motores compatibles con Apache Iceberg, un formato de tabla abierto. Además, facilita la integración de datos de bases de datos operacionales y aplicaciones en tiempo casi real a través de integraciones «zero-ETL».
Microsoft Azure: En el ecosistema de Microsoft Azure, la solución destacada es Azure Databricks. Esta plataforma de lakehouse abierta, construida sobre Delta Lake (una capa de almacenamiento de código abierto), unifica las experiencias para data warehousing, ciencia de datos, ingeniería de datos y casos de uso de IA. Azure Databricks se integra fácilmente con otros servicios de Azure como Microsoft Fabric, Power BI y Azure OpenAI, aprovechando estándares e interfaces abiertas. La plataforma está diseñada para ejecutar cargas de trabajo de warehousing, analítica, ETL, streaming y IA a cualquier escala de manera rentable.
Google Cloud: Google Cloud ofrece una plataforma de Data Lakehouse abierta, gestionada e inteligente, diseñada para unificar y gobernar datos multimodales con alto rendimiento y una integración líder en la industria con la IA de Google. Sus innovaciones clave incluyen:
- BigLake: Proporciona un motor de almacenamiento Iceberg nativo para la interoperabilidad con Cloud Storage. Ofrece gestión unificada de metadatos en tiempo de ejecución, permite análisis avanzados y ciencia de datos, y proporciona gestión automatizada de datos con gobernanza incorporada.
- Google Cloud Serverless for Apache Spark: Ofrece alto rendimiento y procesamiento ultrarrápido sin necesidad de gestión de clústeres, transformando el lakehouse con un inicio rápido y cero sobrecarga operativa.
- Dataplex Universal Catalog: Es la solución unificada de gobernanza de datos a IA para Google Cloud. Este catálogo impulsado por IA centraliza los metadatos empresariales, técnicos y operativos y soporta formatos abiertos como Apache Iceberg para una gobernanza integrada en todo el lakehouse. Cabe destacar que Databricks también ofrece su plataforma Lakehouse en Google Cloud, con una estrecha integración con Google Cloud Storage, BigQuery y Google Cloud AI Platform.
Otros Proveedores y Soluciones Relevantes:
Más allá de los tres grandes proveedores de nube, existen otras soluciones notables en el espacio Lakehouse:
- Snowflake: Aunque es conocido como una plataforma de data warehousing en la nube, Snowflake ha evolucionado para soportar capacidades de Data Lake y actúa como un puente entre Data Lakes y Data Warehouses. Ha adoptado completamente Apache Iceberg para un enfoque de lakehouse abierto, permitiendo a los clientes almacenar datos en un formato abierto e interoperable mientras aprovechan la plataforma de Snowflake.
- Databricks: Como pionero en la arquitectura Lakehouse, Databricks ha impulsado la adopción de Delta Lake como una capa de almacenamiento optimizada que soporta transacciones ACID y aplicación de esquemas.
- Cloudera Data Platform (CDP): Ofrece una distribución de Hadoop para lagos de datos y proporciona soluciones híbridas y multi-cloud, construidas sobre tecnologías Hadoop y open source.
- Dremio: Proporciona un motor de Data Lake que acelera las consultas contra los Data Lakes, ofreciendo una capa semántica para análisis de autoservicio.
- Teradata VantageCloud Lake: Es la plataforma cloud-native de próxima generación de Teradata, diseñada para analíticas modernas y cargas de trabajo de lakehouse, integrando análisis de datos estructurados y no estructurados.
Casos de uso del Data Lake
Los Data Lakes son particularmente adecuados para escenarios que requieren flexibilidad, almacenamiento de datos en bruto y la capacidad de realizar análisis exploratorios:
Los Data Lakes son particularmente adecuados para escenarios que requieren flexibilidad, almacenamiento de datos en bruto y la capacidad de realizar análisis exploratorios:
- Análisis Avanzado y Machine Learning: Son la base para la analítica predictiva, permitiendo a las empresas pronosticar eventos futuros (ej., demanda de productos) y personalizar experiencias de cliente. Facilitan el procesamiento del lenguaje natural (NLP) para análisis de sentimiento en tiempo real a partir de reseñas y redes sociales.
- Almacenamiento y Análisis de Datos IoT (Internet de las Cosas): Los Data Lakes son ideales para capturar y gestionar los vastos volúmenes de datos de alta velocidad generados por dispositivos inteligentes, permitiendo el análisis de patrones para ciudades inteligentes o el monitoreo de equipos.
- Exploración e Investigación de Datos: Permiten a las empresas sumergirse instantáneamente en sus datos para encontrar patrones e información, y son valiosos para la investigación académica y científica al centralizar grandes volúmenes de datos.
- Repositorio de Datos Centralizado: Al consolidar datos de diversas unidades de negocio, los Data Lakes ofrecen una visión holística de la empresa, lo que conduce a una mejor toma de decisiones. También son cruciales para el almacenamiento histórico y el archivo de datos para análisis de tendencias y cumplimiento.
- Dashboards y Reportes en Tiempo Real: Pueden agregar datos de múltiples fuentes para alimentar dashboards en vivo, permitiendo respuestas rápidas a situaciones cambiantes.
- Archivo de Datos y Data Lake-as-a-Service: Ofrecen un método seguro y eficiente para la retención de datos a largo plazo para el cumplimiento normativo y abren nuevas fuentes de ingresos al ofrecer servicios de Data Lake a terceros.
- Casos de Uso Específicos por Industria: En seguros, mejoran el perfilado de clientes y la detección de fraudes. En banca, permiten experiencias de cliente personalizadas y detección de fraudes en tiempo real. En manufactura, optimizan la eficiencia de producción y el mantenimiento predictivo.
Casos de uso del Data Lakehouse
Los Data Lakehouses, al combinar las fortalezas de Data Lakes y Data Warehouses, son plataformas versátiles que abordan una gama aún más amplia de desafíos empresariales:
- Tareas Analíticas Avanzadas: Ideales para procesar todo tipo de datos en una sola ubicación, permitiendo predicción de tendencias, análisis de feedback de clientes, detección de anomalías y Machine Learning para insights más profundos.
- Insights y Dashboards en Tiempo Real: Facilitan la creación de dashboards en vivo para monitorear KPIs y tendencias, permitiendo a los equipos identificar anomalías y actuar rápidamente, mejorando la toma de decisiones.
- Cargas de Trabajo de Ciencia de Datos e IA/ML: La flexibilidad para manejar datos estructurados, semiestructurados y no estructurados en una plataforma unificada beneficia a los científicos de datos y equipos de ML, simplificando el desarrollo y despliegue de modelos avanzados.
- Optimización de Procesos de Business Intelligence: Las herramientas de BI pueden operar directamente sobre los datos crudos en el Lakehouse, eliminando la necesidad de mover o remodelar datos y acelerando la generación de informes y dashboards.
- Análisis de Tendencias Históricas y Cumplimiento: La función de «viaje en el tiempo» de un Data Lakehouse permite un fácil acceso a versiones anteriores de los datos, simplificando el seguimiento de cambios, la comparación de rendimiento y el cumplimiento normativo.
- Garantía de Calidad de Datos y Cumplimiento Normativo: Las características de gobernanza y la gestión eficiente de metadatos en los Lakehouses aseguran datos consistentes y confiables, simplificando la generación de informes de cumplimiento y las auditorías.
- Exploración Ágil de Datos: Permiten a analistas y equipos de negocio acceder y analizar datos rápidamente sin necesidad de moverlos, identificando tendencias y descubriendo información valiosa para una toma de decisiones ágil.
- Construcción de Perfiles de Cliente Completos: Al integrar datos transaccionales estructurados con interacciones de clientes no estructuradas, los Lakehouses ayudan a crear una visión completa de los clientes, permitiendo esfuerzos de marketing personalizados y soluciones dirigidas.
- Procesamiento Eficiente de Datos IoT: Son muy adecuados para aplicaciones IoT debido a su capacidad para manejar grandes volúmenes de datos de streaming en tiempo real, monitoreando el rendimiento de dispositivos y prediciendo necesidades de mantenimiento.
- Oportunidades de Monetización de Datos: Las organizaciones pueden aprovechar los Data Lakehouses para procesar y refinar sus datos, creando nuevas oportunidades de ingresos al ofrecer datos como servicio o segmentar clientes.
- Casos de Uso por Industria: Benefician a organizaciones en una amplia gama de industrias, incluyendo salud (registros de salud, dispositivos médicos), finanzas (transacciones, gestión de riesgos), retail (interacciones con clientes, puntos de venta), manufactura (procesos de producción, cadena de suministro) y gobierno (registros fiscales, datos de salud pública).
Consejos para una migración exitosa a un Lakehouse
Para asegurar una transición fluida y aprovechar al máximo los beneficios de un Data Lakehouse, se recomiendan los siguientes pasos:
- Simplificar Configuración y Control de Acceso: Definir políticas de seguridad tempranamente, utilizando controles de acceso basados en roles (RBAC) y automatizando la configuración de clústeres.
- Optimizar Tiempos de Inicio del Motor de Cómputo: Automatizar los procesos de inicio de motores de cómputo y clústeres, y considerar opciones serverless para minimizar demoras y costos.
- Asegurar Alta Calidad de Datos: Establecer un marco de gobernanza robusto con procesos de validación claros. Emplear herramientas como Delta Lake o Apache Iceberg para aplicar la gobernanza de esquemas y automatizar pruebas para identificar inconsistencias.
- Gestionar Costos Eficazmente: Monitorear regularmente el uso de recursos, implementar políticas de escalado dinámico y dimensionar adecuadamente los clústeres.
- Comenzar con Cargas de Trabajo Incrementales: En lugar de una migración completa, iniciar con una carga de trabajo o conjunto de datos pequeño. Probar el rendimiento y la escalabilidad del Lakehouse y expandir gradualmente.
- Aprovechar Formatos y Herramientas Abiertas: Utilizar formatos de archivo de código abierto como Apache Parquet o Delta Lake para máxima flexibilidad y evitar el bloqueo de proveedor.
- Prepararse para Diversos Tipos de Datos: Realizar un inventario de los tipos de datos actuales y futuros, seleccionando herramientas optimizadas para manejar formatos estructurados, semiestructurados y no estructurados.
Conclusiones
La evolución de las arquitecturas de datos, desde los Data Warehouses hasta los Data Lakes y, finalmente, los Data Lakehouses, refleja una búsqueda incesante por una solución que pueda manejar la creciente complejidad y volumen de los datos empresariales. Los Data Warehouses, aunque excelentes para datos estructurados y BI, demostraron ser demasiado rígidos y costosos para la explosión de datos brutos y heterogéneos. Los Data Lakes surgieron como una respuesta flexible y económica, capaces de almacenar cualquier tipo de dato en su formato original, lo que abrió las puertas a la analítica avanzada y el Machine Learning. Sin embargo, esta flexibilidad sin control a menudo condujo a problemas de gobernanza y calidad de datos, creando «pantanos de datos» que minaron la confianza y la utilidad.
El Data Lakehouse emerge como la arquitectura dominante actual, al abordar estas limitaciones al integrar la fiabilidad y las capacidades de gestión de datos de los Data Warehouses directamente en el Data Lake. La clave de esta convergencia reside en la sofisticada capa de metadatos, habilitada por formatos de tabla abiertos como Apache Iceberg y Delta Lake. Esta capa permite características críticas como las transacciones ACID, la aplicación de esquemas y un rendimiento de consultas mejorado, todo ello sin la necesidad de mover los datos a un sistema separado. El resultado es una plataforma unificada que puede soportar tanto las cargas de trabajo tradicionales de Business Intelligence como las exigentes demandas de la Ciencia de Datos y la Inteligencia Artificial en un mismo repositorio de datos.
En esencia, el Data Lakehouse no es solo una nueva tecnología, sino un cambio de paradigma que democratiza el acceso a los datos y simplifica la pila tecnológica. Al eliminar los silos de datos y reducir la duplicación, las organizaciones pueden obtener una visión más coherente y completa de su negocio, acelerando la toma de decisiones y la innovación. Si bien la adopción de un Data Lakehouse puede implicar una inversión inicial y una curva de aprendizaje debido a su relativa novedad, los beneficios a largo plazo en términos de flexibilidad, escalabilidad, costo-efectividad, calidad de datos y soporte integral para todo tipo de análisis lo posicionan como la arquitectura preferida para las empresas modernas impulsadas por los datos. La elección de la solución adecuada dependerá de la estrategia de nube de cada organización y de la madurez de sus equipos de datos, pero la dirección es clara: hacia una plataforma de datos unificada, abierta e inteligente.
———————————————-
Fuentes: